Este producto no es compatible con el sitio Datadog seleccionado. ().
Observability Pipelines no está disponible en el sitio US1-FED Datadog.
Datadog recomienda actualizar Observability Pipelines Worker (OPW) con cada versión menor y de parche o, como mínimo, mensualmente.
Actualizar a una versión mayor de OPW y mantenerla actualizada es la única manera compatible de obtener las últimas funcionalidades, correcciones y actualizaciones de seguridad de OPW.
Información general
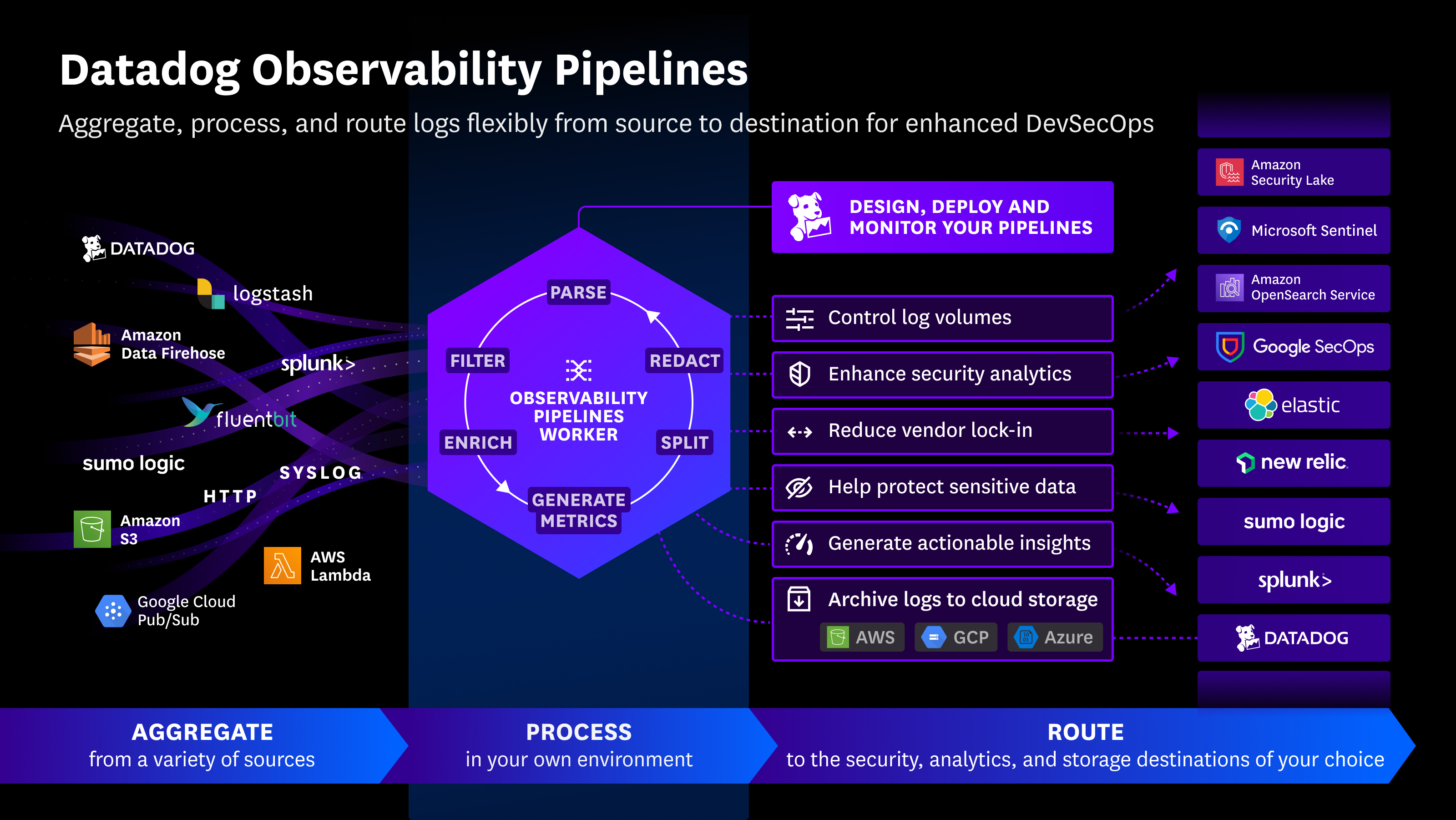
Observability Pipelines te permite recopilar y procesar logs dentro de tu propia infraestructura, antes de enrutarlos a las integraciones aguas abajo. Utilza [plantillas] (#start-building-pipelines-with-out-of-the-box-templates) predefinidas para crear y desplegar pipelines basados en tu caso de uso.
Observability Pipelines Worker es el software que se ejecuta en tu infraestructura. Agrega, procesa y enruta de forma centralizada tus logs en función de tu caso de uso. Esto significa que puedes ocultar datos confidenciales, preprocesar logs y determinar a qué destinos deben ir, antes de que los logs abandonen tu entorno.
La interfaz de usuario de Observability Pipelines proporciona un plano de control para gestionar tus Observability Pipelines Workers. Desde allí puedes crear, editar y cambiar pipelines en tus Workers. También puedes habilitar monitores para tus pipelines de forma que puedas evaluar su estado.
Para ver las opciones de arranque y obtener más información sobre la configuración del Worker con Kubernetes, consulta Configuraciones avanzadas.
Explorar Observability Pipelines
Crear pipelines con plantillas predefinidas
Las plantillas se crean para los siguientes casos de uso:
Control del volumen de logs
Los logs sin procesar son ruidosos, y sólo algunos son útiles para una mayor búsqueda y análisis durante las investigaciones. Utiliza la plantilla Control del volumen de logs para determinar qué logs debes enviar a tu solución indexada, como una solución SIEM o de gestión de logs. Esto te ayudará a aumentar el valor de tus logs indexados y también a mantenerte dentro de tu presupuesto previsto.
Logs de doble envío
A medida que tu organización crece, también cambian tus necesidades de observabilidad de diferentes casos de uso, como la seguridad, el archivado y la gestión de logs. Esto podría llevar a que necesites probar diferentes soluciones de archivado, SIEM y de gestión de logs. Sin embargo, la gestión de pipelines de logs con diferentes soluciones puede ser complicada. Utiliza la plantilla Logs de doble envío para agregar de forma centralizada, procesar y enviar copias de tus logs a diferentes destinos.
Archivar logs
Utiliza la plantilla Archivar logs para almacenar logs en una solución de almacenamiento en la nube (Amazon S3, Google Cloud Storage o Azure Storage). Los logs archivados se almacenan en un formato rehidratable en Datadog, de modo que puedan rehidratarse en Datadog cuando sea necesario. Esto es útil cuando:
Tienes un gran volumen de logs ruidosos, pero puede que necesites indexarlos en Datadog Log Management ad hoc para una investigación.
Estás migrando a Datadog Log Management y quieres contar con un historial de los logs luego de la migración.
Tienes una política de conservación para cumplir con los requisitos de cumplimiento, pero no necesariamente necesitas indexar esos logs.
Logs divididos
Cuando tengas logs de diferentes servicios y aplicaciones, puede que necesites enviarlos a diferentes servicios posteriores para su consulta, análisis y alertas. Por ejemplo, es posible que quieras enviar logs de seguridad a una solución SIEM y logs de DevOps a Datadog. Utiliza la plantilla Dividir logs para preprocesar tus logs por separado para cada destino antes de enviarlos a los procesos posteriores.
Ocultar datos confidenciales
Utiliza la plantilla Ocultar datos confidenciales para detectar y ocultar información confidencial in situ. El procesador de análisis de datos confidenciales de Observability Pipelines proporciona 70 reglas de análisis listas predefinidas, pero también puedes crear tus propias reglas de análisis personalizadas utilizando expresiones regulares. Las reglas OOTB reconocen patrones estándar como números de tarjetas de crédito, direcciones de correo electrónico, direcciones IP, claves API, claves SSH y tokens de acceso.
Enriquecimiento de logs
Todos los diferentes servicios, sistemas y aplicaciones de tu organización generan logs que contienen capas de información y tienen diferentes formatos. Esto puede dificultar la extracción a la hora de buscar y analizar los datos que necesitas para una investigación. Utiliza la plantilla Enriquecimiento de logs para estandarizar tus logs y enriquecerlos con información, como los datos de una tabla de referencia.
Generar métricas
Algunas fuentes de logs, como los cortafuegos y los dispositivos de red, generan un gran volumen de eventos de logs que contienen datos de logs que no es necesario almacenar. A menudo, sólo quieres ver un resumen de los logs y compararlos con los datos históricos. Las métricas basadas en logs también son una forma rentable de resumir datos de logs de todo tu flujo (stream) de ingestión. Utiliza la plantilla Generar métricas para generar un recuento de métricas de logs que coincidan con una consulta o una métrica de distribución de un valor numérico contenido en los logs, como la duración de una solicitud.
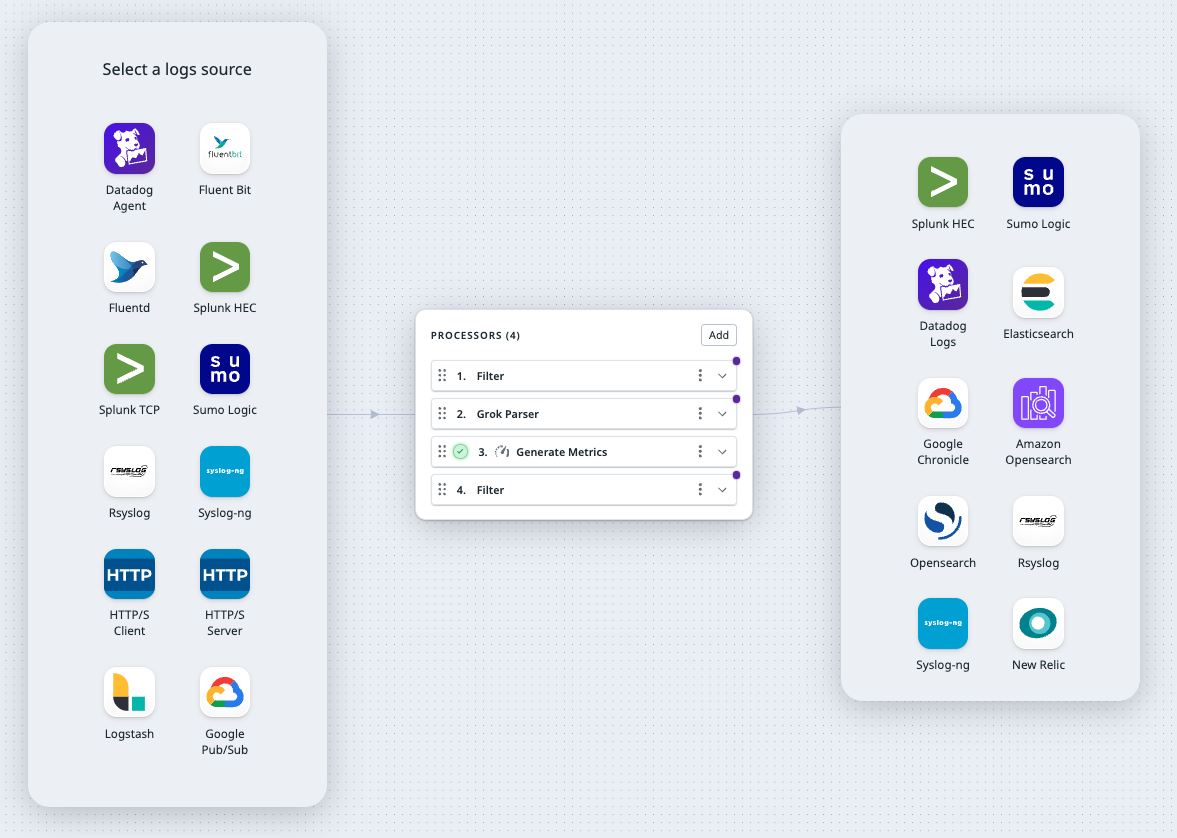
Crear pipelines en la interfaz de usuario de Observability Pipelines
Crea tus pipelines en la interfaz de usuario de Observability Pipelines. Después de seleccionar una de las plantillas predefinidas, el flujo de trabajo de incorporación te guía a través de la configuración de tu fuente, tus procesadores y tus destinos. La página de instalación proporciona instrucciones sobre cómo instalar el Worker en tu entorno (Docker, Kubernetes, Linux o CloudFormation).
Activar monitores predefinidos para tus componentes de pipelines
Después de crear tu pipeline de distribución, activa los monitores predefinidos para recibir alertas cuando:
Aumentan los errores de un componente. Esto podría ocurrir porque el componente está procesando datos en formatos inesperados.
El Observability Pipelines Worker tiene un uso elevado de CPU o de memoria.
Existen picos en los datos descartados por un componente.