Detección de la disponibilidad de las aplicaciones utilizando Network Insights
Cuando las aplicaciones dependen unas de otras, una conectividad deficiente o unas llamadas lentas a servicios pueden provocar errores y latencia en la capa de la aplicación. Cloud Network Monitoring (CNM) de Datadog ofrece información práctica para resolver problemas de aplicaciones y red mediante la captura, el análisis y la correlación de métricas de red como latencia, pérdida de paquetes y rendimiento en varias aplicaciones y servicios.
Detección de de servicios y conectividad
CNM está diseñado para rastrear el tráfico entre entidades, determinar qué recursos se están comunicando e informar de su estado.
Para examinar un flujo de tráfico básico entre entidades, sigue los siguientes pasos:
En la página de análisis de redes, configura tus filtros desplegables Ver clientes como y Ver servidores como para agrupar por etiquetas (tags) de service para examinar un flujo servicio-a-servicio. Aquí puedes observar la unidad básica de tráfico: una IP de origen que se comunica a través de un puerto con una IP de destino en un puerto.
Cada fila suma 5 minutos de conexiones. Aunque es posible que reconozcas algunas IP como direcciones específicas o hosts, dependiendo de tu familiaridad con la red, esto se convierte en un reto cuando se trata de redes más amplias y complejas. El nivel de agregación más relevante implica correlacionar cada host o contenedor asociado a estas IP con etiquetas de Datadog, como service, availability zone, pod y más, como se muestra en el siguiente ejemplo.
Limita los resultados de las búsquedas utilizando filtros. Por ejemplo, para ver el tráfico de red de todos tus pods de orders-sqlserver* por host y zona de disponibilidad, utiliza el filtro client_pod_name:orders-sqlserver*:
Este primer paso te permite monitorizar tus redes más complejas y obtener información sobre las conexiones entre los endpoints de tu entorno, como máquinas virtuales, contenedores, servicios, regiones en la nube, centros de datos, etc.
Seguimiento de dependencias servicio-a-servicio
CNM realiza un seguimiento de las dependencias entre servicios, lo que resulta esencial para garantizar el rendimiento del sistema. Ayuda a verificar las conexiones importantes y destaca los volúmenes de tráfico, garantizando que todas las dependencias críticas estén operativas.
Por ejemplo, una posible causa de latencia de un servicio podría ser que se dirija demasiado tráfico a un endpoint de destino, lo que desbordaría su capacidad para gestionar eficazmente las solicitudes entrantes.
Para analizar la causa de la latencia de un servicio, sigue estos pasos:
En la página de análisis de redes, agrega el tráfico por service y filtra por la región en la nube en la que puedas estar notando alertas o latencias de servicios. Esta vista muestra todas las rutas de dependencia de servicio-a-servicio en esa región.
Ordena la tabla de dependencias en función de las retransmisiones o la latencia para identificar las conexiones con la degradación de rendimiento más significativa. Por ejemplo, si observas un número inusualmente alto de conexiones TCP establecidas junto con picos de retransmisiones y latencia, esto puede indicar que el origen está saturando de solicitudes la infraestructura del destino.
Haz clic en una de las rutas de tráfico de esta página para abrir el panel lateral. El panel lateral proporciona telemetría más detallada para ayudarte a depurar mejor las dependencias de red.
Mientras estás en la vista del panel lateral, consulta la pestaña el Flujos para determinar si el protocolo de comunicación es TCP o UDP y revisar métricas como RTT, Jitter y los paquetes enviados y recibidos. Si estás investigando un alto recuento de retransmisiones, esta información puede ayudarte a identificar la causa.
CNM de Datadog consolida los datos distribuidos relevantes de trazas (traces), logs e infraestructuras en una única vista, lo que te permite identificar y rastrear los problemas hasta la solicitud que se origina en una aplicación.
En el ejemplo siguiente, consulta la pestaña Trazas en Análisis de redes para ver la distribución de trazas de las solicitudes entre los endpoints de origen y destino, lo que puede ayudarte a localizar dónde se producen los errores a nivel de la aplicación.
Para identificar si un problema es de aplicación o de red, sigue estos pasos:
Ve a Infraestructura > Red en la nube > Análisis.
En los gráficos del Resumen, haz clic en una línea de comunicación que tenga mucho volumen y un tiempo de RTT elevado:
Haz clic en Isolate this series (Aislar estas series). Se abre una página que te permite observar el tráfico de red sólo en esta línea de comunicación.
En esta página, haz clic en una de las rutas de comunicación de red y, a continuación, haz clic en la pestaña Flujos para observar el tiempo de RTT:
En esta página, CNM correlaciona el tiempo de ida y vuelta (RTT) de una métrica de red con la latencia de la solicitud de la aplicación para ayudar a identificar si el problema es de la red o de la aplicación. En este ejemplo concreto, observa que el tiempo de RTT es ligeramente elevado, pero ha disminuido con el tiempo y debe investigarse más a fondo.
En esta misma página, haz clic en la pestaña Trazas e investiga la columna Duración:
Observa que aunque la latencia de red (RTT) es elevada, la latencia de solicitud de la aplicación (Duración) es normal, por lo que, en este caso, el problema está probablemente relacionado con la red y no hay necesidad de investigar el código de la aplicación.
Por el contrario, si la latencia de red es estable, pero la latencia de la aplicación (Duración) es elevada, es probable que el problema provenga de la aplicación. En este caso puedes explorar las trazas a nivel del código haciendo clic en una de las rutas del servicio en la pestaña Trazas para encontrar la causa raíz, lo que le lleva al gráfico de llamas de APM relacionado con este servicio:
Mapa de red
El Mapa de redes de Datadog proporciona una representación visual de la topología de tu red, lo que te ayuda a identificar particiones, dependencias y cuellos de botella. Consolida los datos de red en un mapa direccional, facilitando el aislamiento de áreas problemáticas. Además, visualiza el tráfico de red entre cualquier objeto etiquetado de tu entorno, desde services a pods y cloud regions.
Para redes complejas en grandes entornos en contenedores, el Mapa de red de Datadog simplifica la resolución de tus problemas mediante el uso de flechas direccionales, o bordes, para visualizar los flujos de tráfico en tiempo real entre contenedores, pods y despliegues, incluso a medida que cambian los contenedores. Esto te permite detectar ineficiencias y errores de configuración. Por ejemplo, el mapa puede revelar si los pods de Kubernetes dentro del mismo clúster se están comunicando a través de un controlador de entrada, en lugar de hacerlo directamente entre sí, lo que indica un error de configuración que puede causar un aumento de la latencia.
Para identificar si puede haber un problema de comunicación con tus pods de Kubernetes y sus servicios subyacentes, sigue los siguientes pasos:
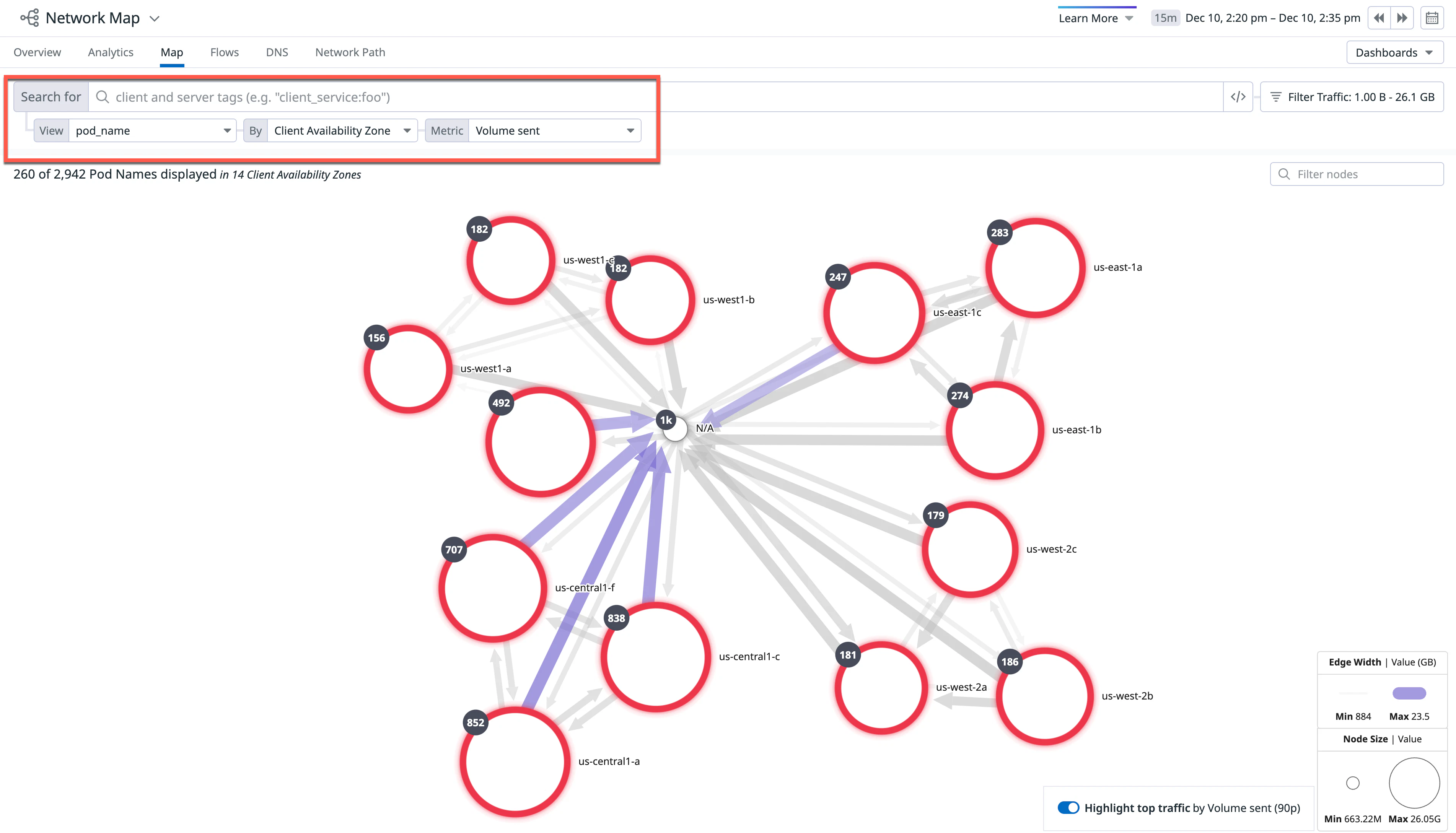
En el Mapa de red, define el desplegable Vista en pod_name, el desplegable Por en “Zona de disponibilidad del cliente” y el desplegable Métrica en “Volumen enviado” (esta es la métrica que quieres que representen tus bordes):
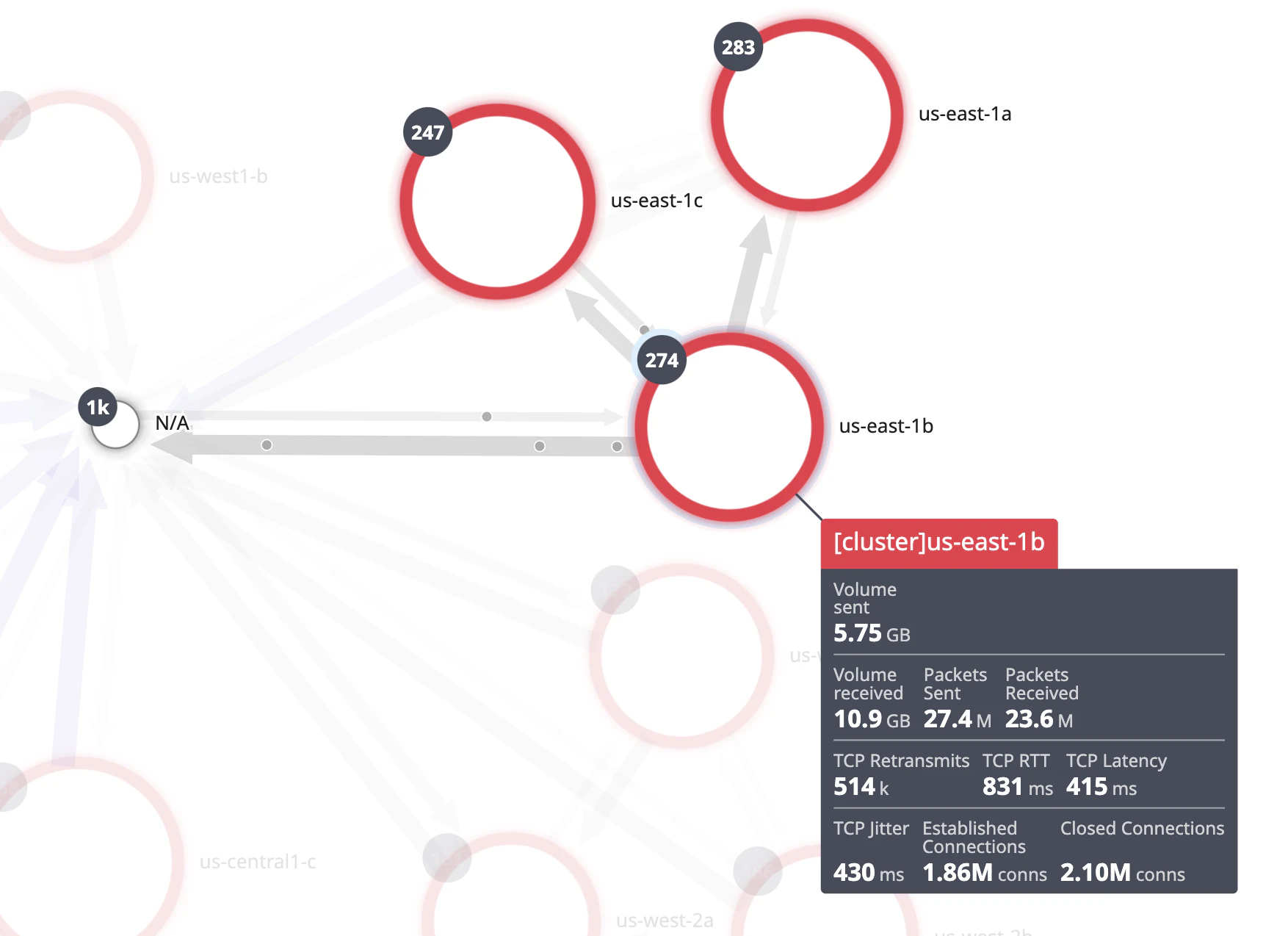
Pasa el ratón sobre un nodo para observar los bordes (o flechas direccionales) y visualizar el flujo de tráfico entre clústeres y las zonas de disponibilidad. En este ejemplo concreto, observa que existen bordes entre todos tus pods. Si no hay bordes, esto podría significar que existe un problema de configuración.
El grosor del borde está asociado a la métrica elegida en el desplegable. En este ejemplo concreto, un borde más grueso se asocia con la métrica volume sent . Si quieres, también puedes volver directamente a la página de análisis de redes haciendo clic directamente en el borde punteado para investigar más a fondo las conexiones de red.
Mallas de servicios
Las mallas de servicios como Istio ayudan a gestionar la comunicación entre microservicios, pero añaden complejidad a la monitorización introduciendo capas de abstracción. CNM de Datadog simplifica esta complejidad visualizando los flujos de tráfico a través de redes gestionadas por Istio y proporcionando una visibilidad completa del entorno de Istio. Datadog monitoriza métricas clave como el ancho de banda y el rendimiento de las solicitudes, registra el estado del plano de control y rastrea las solicitudes de aplicaciones a través de la malla.
Además, Datadog es compatible con la monitorización Envoy, correlacionando los datos de Istio con la malla de proxies de Envoy. Dado que el tráfico se enruta a través de los sidecars Envoy, Datadog los etiqueta como contenedores, lo que permite a los usuarios identificar y diagnosticar problemas de latencia entre pods y determinar si están relacionados con la malla de servicios.
Referencias adicionales
Más enlaces, artículos y documentación útiles: