Monitor de checks de servicios
Los monitores de checks de servicios incluyen cualquier check de servicios no informado por una de las más de 1,000 integraciones incluidas con el Agent. Los checks de servicios pueden enviarse a Datadog utilizando un check del Agent personalizado, DogStatsD, o la API. Para obtener más información, consulta Información general en la sección Check de servicios.
Creación de un monitor
Para crear un monitor de check de servicios en Datadog, utiliza la navegación principal: Monitors –> New Monitor –> Service Check (Monitores > Nuevo monitor > Check de servicios).
Elegir un check de servicios
Elige un check de servicios en el menú desplegable.
Elige el contexto del monitor
Selecciona los contextos para monitorizar eligiendo nombres de host, etiquetas (tags), o elige All Monitored Hosts. Si necesitas excluir determinados hosts, utiliza el segundo campo para hacer una lista de nombres o etiquetas.
- El campo de inclusión utiliza la lógica
AND. Todos los nombres de hosts y las etiquetas introducidos deben estar presentes en un host para que este se incluya. - El campo de exclusión utiliza la lógica
OR. Se excluye cualquier host con un nombre de host o una etiqueta introducidos.
Definir condiciones de alerta
En esta sección, elige entre una Alerta de check o una Alerta de clúster:
Una alerta de check rastrea los estados consecutivos enviados por cada agrupación de checks y los compara con tus umbrales.
Configura la alerta de check:
Activa una alerta separada para cada <GROUP> que informa de tu check.
- La agrupación de checks se especifica a partir de una lista de agrupaciones conocidas o puedes especificarla tú. En los monitores de checks de servicios la agrupación por checks es desconocida, por lo que debes especificarla.
Activa la alerta después de un número de fallos consecutivos: <NUMBER>
- Elige cuántas ejecuciones consecutivas con el estado
CRITICAL activan una notificación. Por ejemplo, para recibir una notificación inmediatamente cuando falla tu check, activa la alerta de monitor con el estado crítico 1.
Selecciona Do not notify o Notify para el estado desconocido.
- Si se selecciona
Notify, una transición de estado a UNKNOWN activa una notificación. En la página de estado del monitor, la barra de estado de un grupo en estado UNKNOWN utiliza el gris para NODATA. El estado general del monitor permanece en OK.
Resuelve la alerta después de seleccionar intentos sin errores consecutivos: <NUMBER>.
- Elige cuántas ejecuciones consecutivas con el estado
OK resuelven la alerta. Por ejemplo, para asegurarte de que se soluciona un problema, resuelve el monitor con los estados 4 OK .
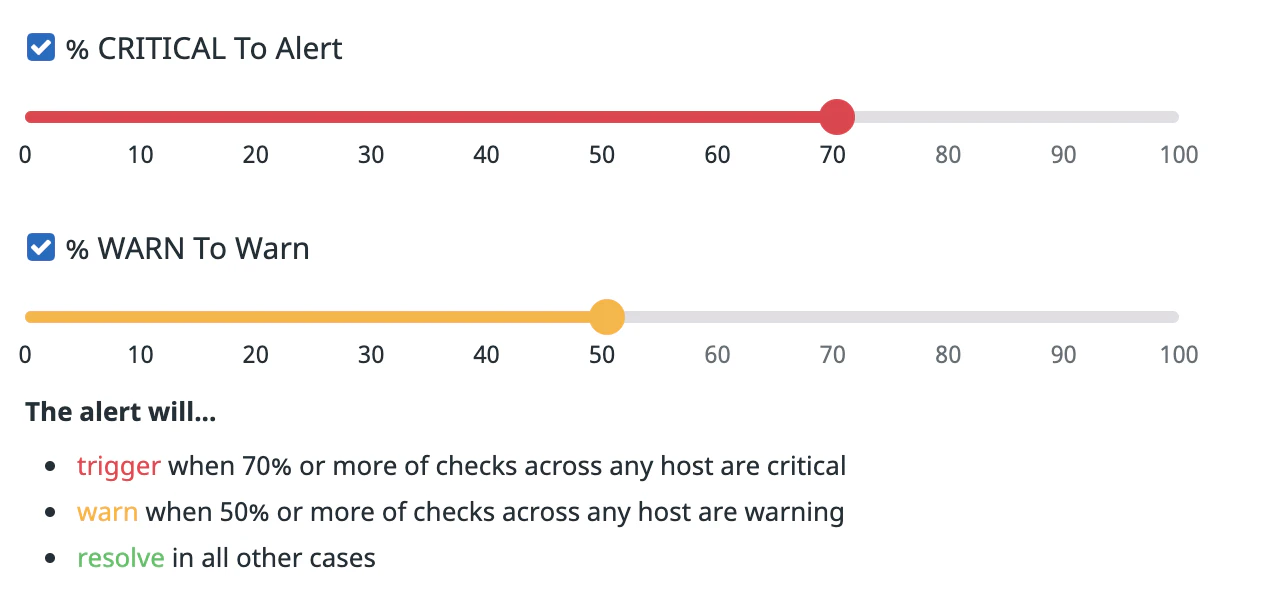
Una alerta de clúster calcula el porcentaje de checks en un estado determinado y lo compara con tus umbrales.
Cada check etiquetado con una combinación distinta de etiquetas se considera un check distinto en el clúster. Solo el estado del último check de cada combinación de etiquetas se tiene en cuenta en el cálculo del porcentaje del clúster.
Por ejemplo, un monitor de checks de clúster agrupado por entornos puede enviar alertas si más del 70% de los checks en cualquiera de los entornos presentan un estado CRITICAL y avisa si más del 70% de los checks en cualquiera de los entornos presentan un estado WARN.
Para configurar una alerta de clúster:
Decide si quieres agrupar o no tus checks según una etiqueta. Ungrouped calcula el porcentaje de estado de todas las fuentes. Grouped calcula el porcentaje de estado por grupo.
Selecciona el porcentaje para los umbrales de alerta y de advertencia. Solo se requiere un parámetro (alerta o advertencia).
Condiciones de alerta avanzadas
Consulta la documentación Configuración de monitores para obtener información sobre las opciones Sin datos, Resolución automática y Retraso de nuevo grupo.
Notificaciones
Para obtener instrucciones detalladas sobre la sección Configurar notificaciones y automatizaciones, consulta la página Notificaciones.
Para leer más
Más enlaces, artículos y documentación útiles: