La detección de anomalías es una función algorítmica que identifica cuando una métrica se comporta de forma diferente a como lo ha hecho en el pasado y tiene en cuenta las tendencias, el día de la semana específico y los patrones de horas del día. Es adecuada para métricas con tendencias marcadas y patrones recurrentes, difíciles de monitorizar mediante alertas con umbrales.
Por ejemplo, la detección de anomalías te puede ayudar a detectar cuando el tráfico de tu web es inusualmente bajo en un día laborable, por ejemplo por la tarde, pero luego se normaliza por la noche. O piensa por ejemplo en una métrica que pueda medir el número de accesos a tu sitio web en constante crecimiento. Dado que ese número aumenta a diario, cualquier umbral quedaría obsoleto, mientras que la detección de anomalías puede avisarte si se produce un descenso inesperado, lo que podría indicar un problema con el sistema de inicio de sesión.
Creación de un monitor
Para crear un monitor de anomalías en Datadog utiliza la navegación principal: Monitors –> New Monitor –> Anomaly (Monitores > Nuevo monitor > Anomalía).
Definir la métrica
Cualquier métrica que informe a Datadog está disponible para monitores. Para obtener más información, consulta la página Monitor de métricas.
Nota: La función para anomalies utiliza el pasado para predecir lo que se espera en el futuro, por lo que su uso en una métrica nueva podría no dar buenos resultados.
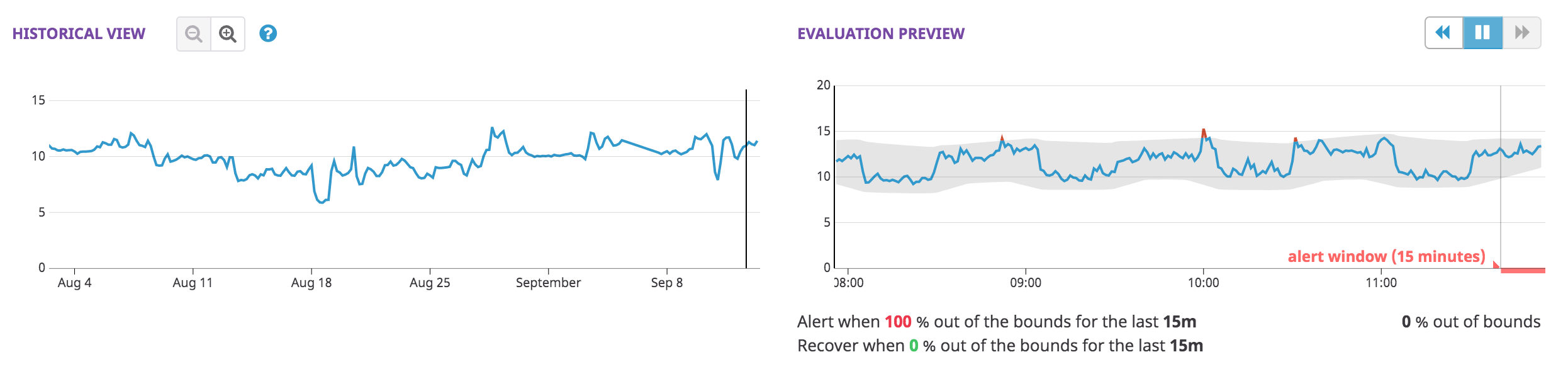
Después de definir la métrica, el monitor de detección de anomalías proporciona dos gráficos de vista previa en el editor:
- La Vista del historial te permite explorar la consulta monitorizada en diferentes escalas temporales, para comprender mejor por qué los datos pueden considerarse anómalos o no anómalos.
- La Vista previa de evaluación es más extensa que la ventana de alertas y ofrece una visión de lo que el algoritmo de anomalías tiene en cuenta al calcular los límites.
Definir tus condiciones de alerta
Activa una alerta si los valores han estado above or below, above o below de los límites durante los últimos 15 minutes, 1 hour, etc. o custom para establecer un valor entre 15 minutos y 24 horas. Ejecuta una recuperación si los valores están dentro de los límites durante al menos 15 minutes, 1 hour, etc. o custom para establecer un valor entre 15 minutos y 24 horas.
- Detección de anomalías
- con la opción por defecto (
above or below), una métrica se considera anómala si está fuera del rango gris de anomalías. También puedes especificar si los rangos se consideran anómalos cuando los valores sólo están above o below. - Ventana de activación
- la cantidad de tiempo necesario para que la métrica sea anómala antes de que se active la alerta. Nota: Si la ventana de alertas es demasiado corta, podrías recibir falsas alarmas generadas por falsos ruidos.
- Ventana de recuperación
- la cantidad de tiempo necesario para que la métrica deje de considerarse anómala, permitiendo la recuperación de la alerta. Se recomienda configurar la Ventana de recuperación con el mismo valor que la Ventana de activación.
Nota: El rango de valores aceptados para la Ventana de Recuperación depende de la Ventana de activación y del Umbral de Alerta, para asegurar que el monitor no cumpla la condición de recuperación y la de alerta al mismo tiempo.
Ejemplo:
Threshold: 50%Trigger window: 4h
El rango de valores aceptados para la ventana de recuperación oscila entre 121 minutos (4h*(1-0.5) +1 min = 121 minutes) y 4 horas. Configurar una ventana de recuperación de menos de 121 minutos podría dar lugar a un marco temporal de 4 horas con un 50% de puntos anómalos y los últimos 120 minutos sin puntos anómalos.
Otro ejemplo:
Threshold: 80%Trigger window: 4h
El rango de valores aceptados para la ventana de recuperación oscila entre 49 minutos (4h*(1-0.8) +1 min = 49 minutes) y 4 horas.
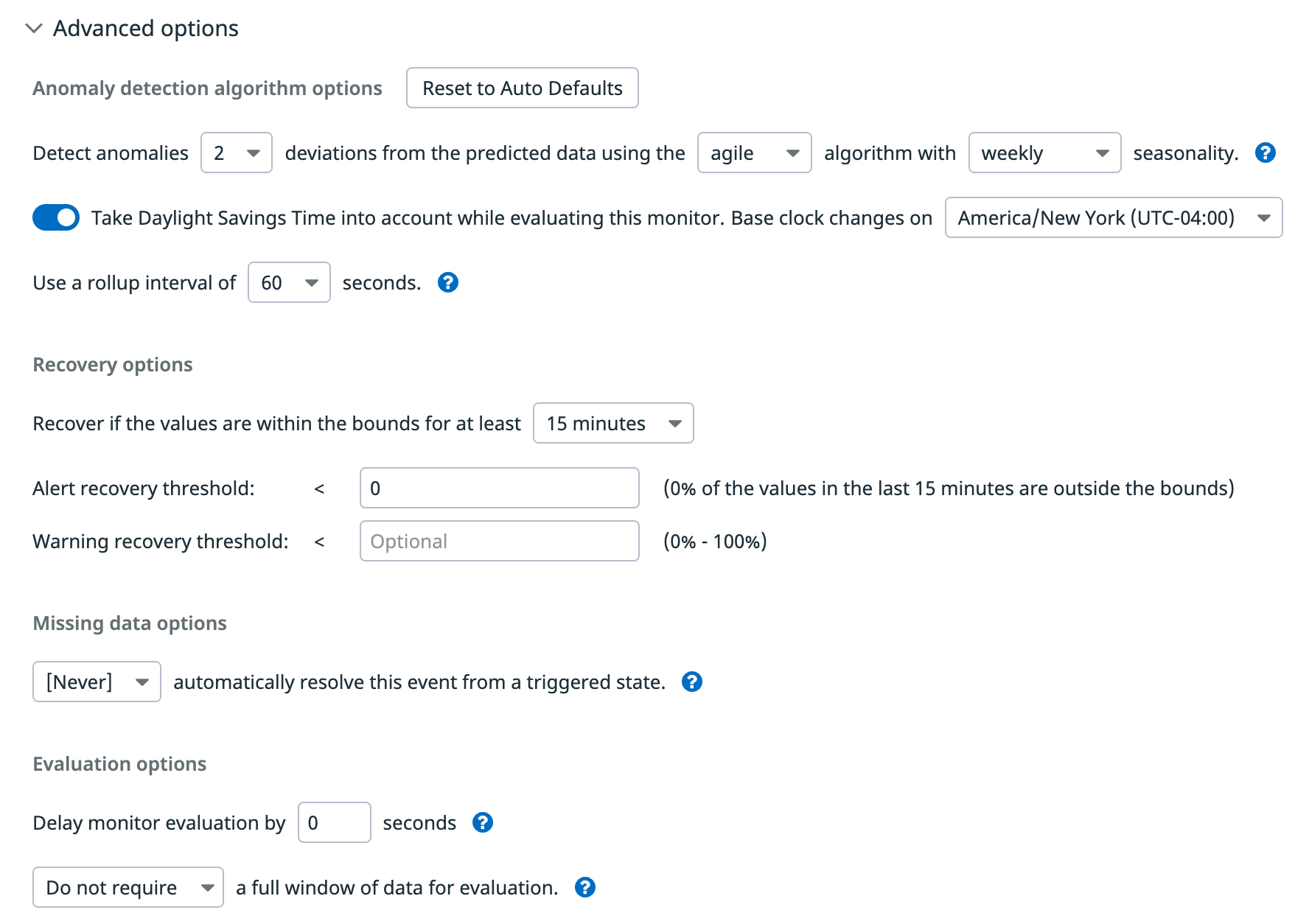
Opciones avanzadas
Datadog analiza automáticamente la métrica elegida y establece varios parámetros. Sin embargo, puedes editar las opciones en Advanced Options (Opciones avanzadas).
- Desviaciones
- el ancho del rango gris. Equivale al parámetro de límites utilizado en la función para anomalías.
- Algoritmo
- algoritmo de detección de anomalías (
basic, agile o robust). - Temporalidad
- temporalidad (
hourly, daily o weekly) del ciclo para que el algoritmo agile o robust analice la métrica. - Cambio de horario estacional
- disponible para la detección de anomalías
agile o robust con temporalidad weekly o daily. Para obtener más información, consulta Detección de anomalías y zonas horarias. - Rollup
- intervalo de rollup.
- Umbrales
- porcentaje de puntos que deben ser anómalos para alertar, advertir y recuperar.
Temporalidad
- Horario
- el algoritmo espera que el mismo minuto después de la hora en punto se comporte como los minutos anteriores después de sus respectivas horas en punto. Por ejemplo, 5:15 se comporta como 4:15, 3:15, etc.
- Diario
- el algoritmo espera que la misma hora de hoy se comporte como la hora de los días pasados. Por ejemplo la hora 17:00 de hoy se comporta como la hora 17:00 de ayer.
- Semanal
- el algoritmo espera que un determinado día de la semana se comporte como los días de las semanas anteriores. Por ejemplo, este martes se comporta como los martes anteriores.
Historial de datos requerido para el algoritmo de detección de anomalías: los algoritmos de machine learning requieren al menos el triple de tiempo de datos históricos que el tiempo de temporalidad elegido para calcular la línea de base.
Por ejemplo:
- La temporalidad semanal requiere al menos tres semanas de datos
- La temporalidad diaria requiere al menos tres días de datos
- La temporalidad horaria requiere al menos tres horas de datos
Todos los algoritmos temporales pueden utilizar hasta seis semanas de datos históricos a la hora de calcular el rango de comportamiento normal esperado para la métrica. Al utilizar una cantidad significativa de datos pasados, los algoritmos evitan dar demasiada importancia a los comportamientos anómalos que puedan haberse producido en un pasado reciente.
Algoritmos de detección de anomalías
- Básicos
- se utilizan cuando las métricas no tienen un patrón de temporalidad repetitivo. Los algoritmos básicos utilizan un simple cálculo de cuantiles móviles retardados para determinar el intervalo de valores esperados. Utilizan pocos datos y se ajustan rápidamente a las condiciones cambiantes, pero no conocen el comportamiento temporal ni las tendencias a más largo plazo.
- Ágiles
- se utilizan cuando cuando las métricas son temporales y se espera que cambien. Los algoritmos se ajustan rápidamente a los cambios de nivel de las métricas. Se trata de una versión robusta del algoritmo SARIMA, que incorpora el pasado inmediato en sus predicciones, lo que permite actualizaciones rápidas para los cambios de nivel, a expensas de ser menos robusto frente a las anomalías recientes de larga duración.
- Robustos
- se utilizan cuando se espera que las métricas temporales sean estables, y los cambios de nivel lentos se consideran anomalías. Un algoritmo de descomposición de tendencias temporales es estable y las predicciones permanecen constantes, incluso en caso de anomalías de larga duración, a expensas de tardar más en responder a los cambios de nivel previstos (por ejemplo, si el nivel de una métrica cambia debido a un cambio de código).
Ejemplos
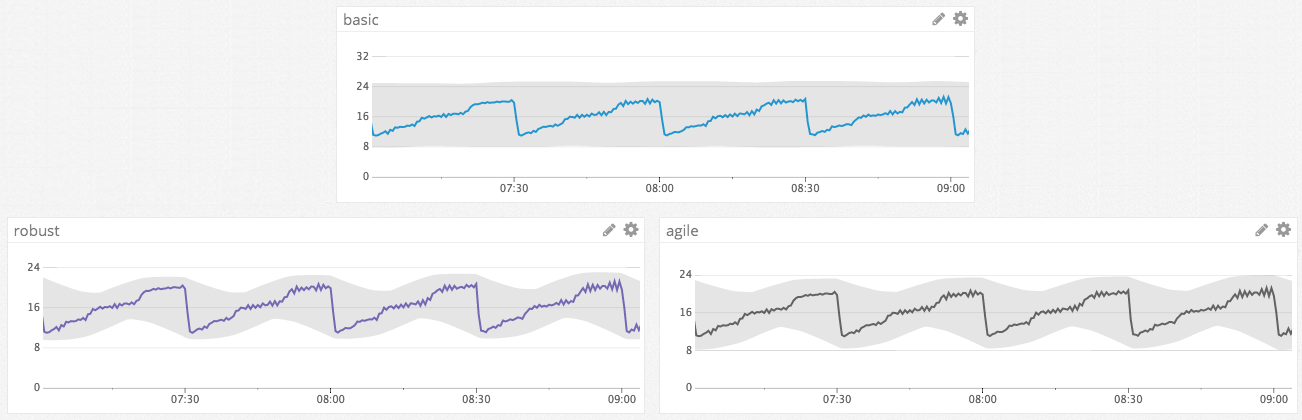
Los siguientes gráficos muestran cómo y cuándo estos tres algoritmos se comportan de forma diferente entre sí.
Comparación de la detección de anomalías para la temporalidad horaria
En este ejemplo, basic identifica con éxito los picos de anomalías fuera del rango normal de valores, pero no incorpora el patrón temporal repetitivo a su rango de valores previstos. Por el contrario, robust y agile reconocen el patrón temporal y pueden detectar anomalías más matizadas; por ejemplo, si la métrica se estabiliza cerca de su valor mínimo. La tendencia también muestra un patrón horario, por lo que la temporalidad horaria funciona mejor en este caso.
Comparación de la detección de anomalías para la temporalidad semanal
En este ejemplo, la métrica muestra un cambio de nivel repentino. Agile se ajusta más rápidamente al cambio de nivel que robust. Además, la amplitud de los límites de robust aumenta para reflejar una mayor incertidumbre tras el cambio de nivel; la amplitud de los límites de agile permanece invariable. Basic no se ajusta bien a este escenario, en el que la métrica muestra un fuerte patrón temporal semanal.
Comparación de las reacciones de los algoritmos al cambio
Este ejemplo muestra cómo reaccionan los algoritmos ante una anomalía de una hora de duración. Robust no ajusta los límites de la anomalía en este escenario, ya que reacciona más lentamente ante los cambios bruscos. Los demás algoritmos empiezan a comportarse como si la anomalía fuera la nueva normalidad. Agile identifica incluso el regreso de la métrica a su nivel original como una anomalía.
Comparación de las reacciones de los algoritmos a las escalas
Los algoritmos tratan a las escalas de forma diferente. Basic y robust son insensibles a las escalas, mientras que agile no lo es. Los gráficos abajo a la izquierda muestran que agile y robust señalan el cambio de nivel como anómalo. A la derecha, se añade 1000 a la misma métrica y agile deja de señalar el cambio de nivel como anómalo, mientras que robust sigue haciéndolo.
Comparación de la detección de anomalías para nuevas métricas
Este ejemplo muestra cómo cada algoritmo trata una métrica nueva. Robust y agile no muestran ningún límite durante las primeras temporalidades (semanales). Basic empieza a mostrar límites poco después de que aparece la métrica por primera vez.
Condiciones de alerta avanzadas
Para obtener instrucciones detalladas sobre las opciones avanzadas de alerta (resolución automática, periodo de espera para la evaluación, etc.), consulta la página de configuración de monitores. Para la opción de ventana de datos de métricas completa, consulta la página Monitor de métricas.
Notificaciones
Para obtener instrucciones detalladas sobre la sección Configurar notificaciones y automatizaciones, consulta la página Notificaciones.
API
Los clientes con un plan de empresa pueden crear monitores de detección de anomalías utilizando el endpoint de la API create-monitor. Datadog recomienda encarecidamente exportar el JSON de monitor para crear la consulta para la API. Al utilizar la página de creación de monitores en Datadog, los clientes se benefician del gráfico de vista previa y del ajuste automático de parámetros para ayuda a evitar una mala configuración del monitor.
Nota: Los monitores de detección de anomalías sólo están disponibles para clientes con un plan de empresa. Los clientes con un plan profesional, que estén interesados en los monitores de detección de anomalías, deben ponerse en contacto con sus representantes de atención al cliente o enviar un correo electrónico al equipo de facturación de Datadog.
Los monitores de anomalías se gestionan utilizando la misma API que otros monitores. Estos campos son exclusivos para monitores de anomalías:
query
La propiedad query del cuerpo de la solicitud debe contener una cadena de consulta con el siguiente formato:
avg(<query_window>):anomalies(<metric_query>, '<algorithm>', <deviations>, direction='<direction>', alert_window='<alert_window>', interval=<interval>, count_default_zero='<count_default_zero>' [, seasonality='<seasonality>']) >= <threshold>
query_window- un marco temporal como
last_4h o last_7d. La ventana temporal que se muestra en los gráficos de las notificaciones debe ser al menos tan grande como la alert_window y se la recomienda por ser unas 5 veces la alert_window. metric_query- una consulta de métricas estándar de Datadog (por ejemplo,
sum:trace.flask.request.hits{service:web-app}.as_count()). algorithmbasic, agile o robust.deviations- un número positivo; controla la sensibilidad de la detección de anomalías.
direction- la direccionalidad de las anomalías que debe activar una alerta:
above, below o both. alert_window- el marco temporal que debe verificarse para buscar anomalías (por ejemplo,
last_5m, last_1h). interval- un número entero positivo que representa el número de segundos del intervalo de rollup. Debe ser menor o igual a un quinto de la duración de la
alert_window. count_default_zero- utiliza
true para la mayoría de los monitores. Utiliza false sólo para enviar una métrica de recuento en la que la falta de un valor no debe interpretarse como un cero. seasonalityhourly, daily o weekly. Excluye este parámetro cuando utilices el algoritmo basic.threshold- número positivo no superior a 1. Fracción de puntos en la
alert_window que deben ser anómalos para que se active una alerta crítica.
A continuación se muestra un ejemplo de consulta de monitor de detección de anomalías, que envía alertas cuando el promedio de CPU del nodo Cassandra se encuentra tres desviaciones estándar por encima del valor ordinario en los últimos 5 minutos:
avg(last_1h):anomalies(avg:system.cpu.system{name:cassandra}, 'basic', 3, direction='above', alert_window='last_5m', interval=20, count_default_zero='true') >= 1
options
La mayoría de las propiedades de options en el cuerpo de la solicitud son las mismas que para otras alertas de consulta, excepto thresholds y threshold_windows.
thresholds- los monitores de anomalías admiten umbrales
critical, critical_recovery, warning y warning_recovery. Los umbrales se expresan como números de 0 a 1 y se interpretan como la fracción de la ventana asociada que es anómala. Por ejemplo, un valor de umbral critical de 0.9 significa que se activa una alerta crítica cuando al menos el 90% de los puntos en la trigger_window (descrita a continuación) son anómalos. O, un valor de warning_recovery de 0 significa que el monitor se recupera del estado de alerta sólo cuando el 0% de los puntos en la recovery_window son anómalos. - El
threshold``critical debe coincidir con el threshold utilizado en la query. threshold_windows- los monitores de anomalías tienen una propiedad
threshold_windows en options. threshold_windows debe incluir las dos propiedades, trigger_window y recovery_window. Estas ventanas se expresan en forma de cadenas de marco temporal, como last_10m o last_1h. La trigger_window debe coincidir con la alert_window de la query. La trigger_window es el rango de tiempo que se analiza en busca de anomalías cuando se evalúa si un monitor debe activarse. La recovery_window es el rango de tiempo que se analiza en busca de anomalías cuando se evalúa si un monitor activado debe recuperarse.
La configuración estándar de umbrales y de ventanas de umbrales tiene el siguiente aspecto:
"options": {
...
"thresholds": {
"critical": 1,
"critical_recovery": 0
},
"threshold_windows": {
"trigger_window": "last_30m",
"recovery_window": "last_30m"
}
}
Solucionar problemas
Leer más
Más enlaces, artículos y documentación útiles: