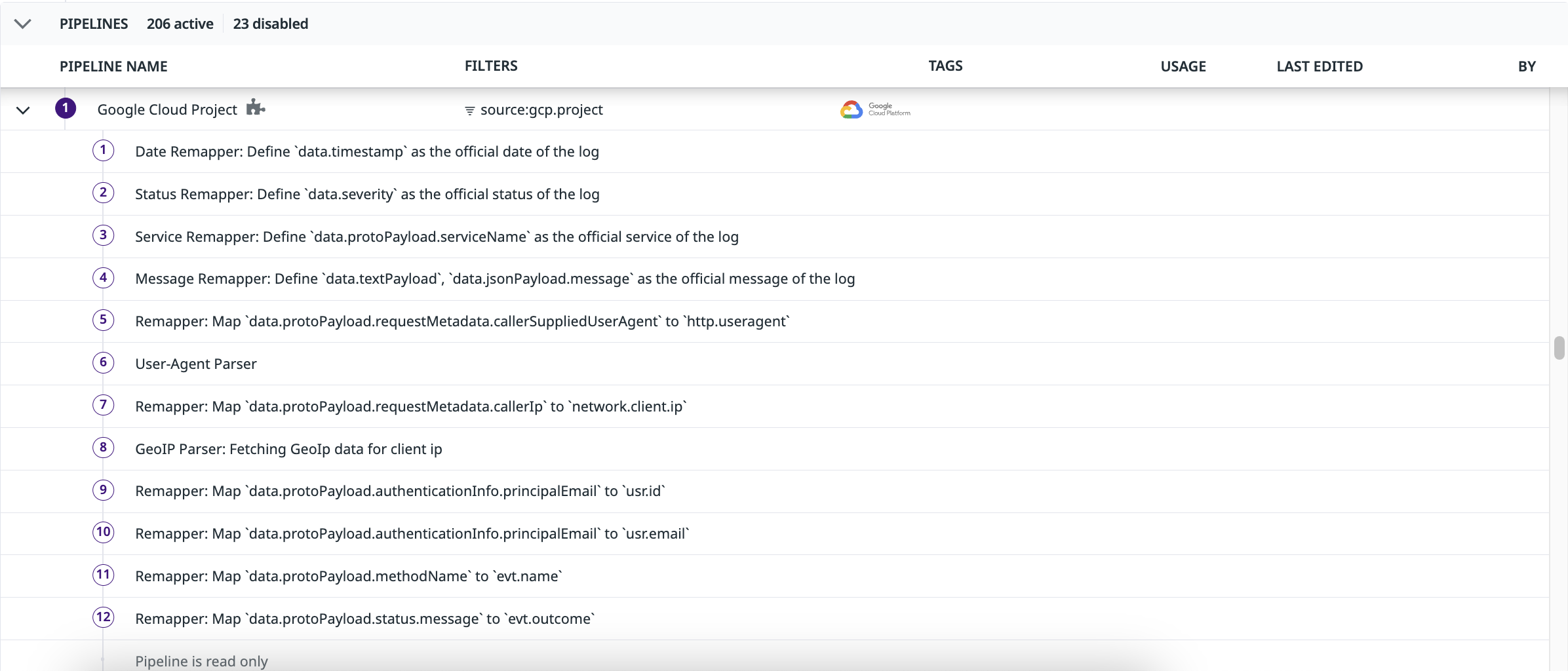
Los procesadores descritos en esta documentación son específicos para entornos de registro basados en la nube. Para analizar, estructurar y enriquecer registros locales, consulta Observability Pipelines.
Un procesador se ejecuta dentro de un Pipeline para completar una acción de estructuración de datos y generar atributos para enriquecer tus registros.
Los registros estructurados deben ser enviados en un formato válido. Si la estructura contiene caracteres inválidos para el parseo, estos deben ser eliminados a nivel del Agente utilizando la función mask_sequences.
Como mejor práctica, se recomienda utilizar un máximo de 20 procesadores por canalización.
Parser Grok
Crea reglas Grok personalizadas para analizar el mensaje completo o un atributo específico de tu evento en bruto. Como mejor práctica, limita tu Grok parser a 10 reglas de análisis. Para más información sobre la sintaxis de Grok y las reglas de parseo, consulte Parsing.
Defina el procesador Grok en la página de Pipelines. Para configurar las reglas de análisis de Grok:
Haga clic en Parse my logs para generar automáticamente un conjunto de tres reglas de análisis basadas en los registros que fluyen a través de la canalización.
Nota: Esta función requiere que los registros correspondientes estén indexados y fluyan activamente. Puede desactivar temporalmente o reducir los filtros de exclusión para permitir que la función detecte registros.
Muestras de registros: Agregue hasta cinco registros de muestra (de hasta 5000 caracteres cada uno) para probar sus reglas de análisis.
Definir reglas de análisis: Escriba sus reglas de análisis en el editor de reglas. A medida que define reglas, el analizador Grok proporciona asistencia de sintaxis:
Sugerencias de coincidencia: Escriba un nombre de regla seguido de %{. Aparece un menú desplegable con los matchers disponibles (como word, integer, ip, date). Seleccione un matcher de la lista para insertarlo en su regla.
MyParsingRule %{
Filter suggestions: Al agregar un filtro con :, un menú desplegable muestra filtros compatibles para el matcher seleccionado.
Test your rules: Seleccione una muestra haciendo clic en ella para activar su evaluación contra la regla de análisis y mostrar el resultado en la parte inferior de la pantalla. Todas las muestras muestran un estado (match o no match), que resalta si una de las reglas de análisis del Grok parser coincide con la muestra.
Si el procesador está habilitado o no. Predeterminado: false.
source
Cadena
Sí
Nombre del atributo de registro a analizar. Predeterminado: message.
samples
Arreglo de cadenas
No
Lista de (hasta 5) registros de muestra para este Grok parser.
grok.support_rules
Cadena
Sí
Lista de reglas de soporte para su Grok parser.
grok.match_rules
Cadena
Sí
Lista de reglas de coincidencia para su Grok parser.
Remapeador de fecha de registro
A medida que Datadog recibe registros, les asigna una marca de tiempo utilizando el valor o valores de cualquiera de estos atributos predeterminados:
timestamp
date
_timestamp
Timestamp
eventTime
published_date
Si tus registros tienen fechas en un atributo que no están en esta lista, utiliza el procesador de remapeo de fechas de registro para definir su atributo de fecha como la marca de tiempo oficial del registro:
Si tus registros no tienen una marca de tiempo que se ajuste a los formatos listados arriba, utiliza el Grok parser para extraer el tiempo epoch de la marca de tiempo a un nuevo atributo. El remapeador de fechas utiliza el nuevo atributo definido.
Para ver cómo se puede analizar un formato de fecha y hora personalizado en Datadog, consulte Parsing dates.
Notas:
Los eventos de registro pueden ser enviados hasta 18 horas en el pasado y dos horas en el futuro.
A partir de ISO 8601-1:2019, el formato básico es T[hh][mm][ss] y el formato extendido es T[hh]:[mm]:[ss]. Las versiones anteriores omitían la T (que representa el tiempo) en ambos formatos.
Si tus registros no contienen ninguno de los atributos predeterminados y no has definido tu propio atributo de fecha, Datadog marca los registros con la fecha en que los recibió.
Si se aplican múltiples procesadores de remapeo de fechas de registro a un registro dado dentro de la canalización, se toma en cuenta el último (de acuerdo con el orden de la canalización).
Define el procesador de remapeo de fechas de registro en la página Pipelines:
{"type":"date-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official Date of the log","is_enabled":false,"sources":["<SOURCE_ATTRIBUTE_1>"]}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Arreglo de cadenas
Sí
Arreglo de atributos de origen.
Remapeador de estado de registro
Utilice el procesador remapeador de estado para asignar atributos como un estado oficial a sus registros. Por ejemplo, agregue un nivel de severidad de registro a sus registros con el remapeador de estado.
Cada valor de estado entrante se mapea de la siguiente manera:
Cadenas que comienzan con emerg o f (sin importar mayúsculas o minúsculas) se mapean a emerg (0)
Cadenas que comienzan con a (sin importar mayúsculas o minúsculas) se mapean a alerta (1)
Cadenas que comienzan con c (sin importar mayúsculas o minúsculas) se mapean a crítico (2)
Cadenas que comienzan con err (sin importar mayúsculas o minúsculas) se mapean a error (3)
Cadenas que comienzan con w (sin importar mayúsculas o minúsculas) se mapean a advertencia (4)
Cadenas que comienzan con n (sin importar mayúsculas o minúsculas) se mapean a aviso (5)
Cadenas que comienzan con i (sin importar mayúsculas o minúsculas) se mapean a info (6)
Cadenas que comienzan con d, t, v, traza, o verbose (sin importar mayúsculas o minúsculas) se mapean a debug (7)
Cadenas que comienzan con o o s, o que coinciden con OK o Éxito (sin importar mayúsculas o minúsculas) se mapean a OK
Todos los demás se mapean a info (6)
Nota: Si se aplican múltiples procesadores remapeadores de estado de registro a un registro dentro de un pipeline, solo se considera el primero en el orden del pipeline. Además, para todos los pipelines que coincidan con el registro, solo se aplica el primer remapeador de estado encontrado (de todos los pipelines aplicables).
Define el procesador remapeador de estado del registro en la página de Pipelines:
{"type":"status-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official status of the log","is_enabled":true,"sources":["<SOURCE_ATTRIBUTE>"]}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Arreglo de cadenas
Sí
Arreglo de atributos de fuente.
Remapeador de servicio
El procesador remapeador de servicio asigna uno o más atributos a tus registros como el servicio oficial.
Nota: Si se aplican múltiples procesadores remapeadores de servicio a un registro dado dentro del pipeline, solo se toma en cuenta el primero (según el orden del pipeline).
Define el procesador remapeador de servicio del registro en la página de Pipelines:
{"type":"service-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official log service","is_enabled":true,"sources":["<SOURCE_ATTRIBUTE>"]}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Arreglo de cadenas
Sí
Arreglo de atributos de fuente.
Remapeador de mensaje del registro
message es un atributo clave en Datadog. Su valor se muestra en la columna Contenido del Explorador de Registros para proporcionar contexto sobre el registro. Puedes usar la barra de búsqueda para encontrar un registro por el mensaje del registro.
Utiliza el procesador remapeador de mensaje del registro para definir uno o más atributos como el mensaje oficial del registro. Define más de un atributo para los casos en que los atributos pueden no existir y hay una alternativa disponible. Por ejemplo, si los atributos de mensaje definidos son attribute1, attribute2 y attribute3, y attribute1 no existe, entonces se utiliza attribute2. De manera similar, si attribute2 no existe, entonces se utiliza attribute3.
Para definir atributos de mensaje, primero utiliza el procesador constructor de cadenas para crear un nuevo atributo de cadena para cada uno de los atributos que deseas usar. Luego, utiliza el remapeador de mensajes de registro para remapear los atributos de cadena como el mensaje.
Nota: Si se aplican múltiples procesadores de remapeo de mensajes de registro a un registro dado dentro de la canalización, solo se toma en cuenta el primero (según el orden de la canalización).
Define el procesador de remapeo de mensajes de registro en la página de Pipelines:
{"type":"message-remapper","name":"Define <SOURCE_ATTRIBUTE> as the official message of the log","is_enabled":true,"sources":["msg"]}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Arreglo de cadenas
Sí
Arreglo de atributos de fuente. Predeterminado: msg.
Remapeador
El procesador de remapeo remapea uno o más atributo(s) o etiquetas de fuente a un atributo o etiqueta de destino diferente. Por ejemplo, puedes remapear el atributo user a firstname para normalizar los datos de registro en el Explorador de Registros.
Si el destino del remapeo es un atributo, el procesador también puede intentar convertir el valor a un nuevo tipo (String, Integer o Double). Si la conversión falla, se preservan el valor y el tipo originales.
Nota: El separador decimal para los valores de Double debe ser ..
Restricciones de nomenclatura
Los caracteres : y , no están permitidos en los nombres de atributos o etiquetas de destino. Además, los nombres de etiquetas y atributos deben seguir las convenciones descritas en Atributos y Alias.
Atributos reservados
El procesador de remapeo no puede ser utilizado para remapear atributos reservados de Datadog.
El atributo host no puede ser remapeado.
Los siguientes atributos requieren procesadores de remapeo dedicados y no pueden ser remapeados con el remapeador genérico. Para remapear cualquiera de los atributos, utiliza el remapeador o procesador especializado correspondiente.
message: Remapeador de mensajes de registro
service: Remapeador de servicio
status: Remapeador de estado del registro
date: Remapeador de fecha de registro
trace_id: Remapeador de trazas
span_id: Remapeador de tramos
Define el procesador de remapeo en la página Pipelines. Por ejemplo, remapea user a user.firstname.
{"type":"attribute-remapper","name":"Remap <SOURCE_ATTRIBUTE> to <TARGET_ATTRIBUTE>","is_enabled":true,"source_type":"attribute","sources":["<SOURCE_ATTRIBUTE>"],"target":"<TARGET_ATTRIBUTE>","target_type":"tag","target_format":"integer","preserve_source":false,"override_on_conflict":false}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
source_type
Cadena
No
Defines if the sources are from log attribute or tag. Predeterminado: attribute.
sources
Array de cadenas
Sí
Array de atributos o etiquetas de fuente
target
Cadena
Sí
Nombre final del atributo o etiqueta para remapear las fuentes.
target_type
Cadena
No
Define si el destino es un registro attribute o un tag. Predeterminado: attribute.
target_format
Cadena
No
Define si el valor del atributo debe ser convertido a otro tipo. Valores posibles: auto, string o integer. Predeterminado: auto. Cuando se establece en auto, no se aplica ninguna conversión.
preserve_source
Booleano
No
Eliminar o preservar el elemento de fuente remapeado. Predeterminado: false.
override_on_conflict
Booleano
No
Sobrescribir o no el elemento de destino si ya está establecido. Predeterminado: false.
Analizador de URL
El procesador del analizador de URL extrae parámetros de consulta y otros parámetros importantes de una URL. Cuando se configura, se producen los siguientes atributos:
Define el procesador de análisis de URL en la página Pipelines:
{"type":"url-parser","name":"Parse the URL from http.url attribute.","is_enabled":true,"sources":["http.url"],"target":"http.url_details"}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Array de cadenas
No
Array de atributos de fuente. Predeterminado: http.url.
target
Cadena
Sí
Nombre del atributo padre que contiene todos los detalles extraídos del sources. Predeterminado: http.url_details.
Analizador de User-Agent
El procesador de análisis de user-agent toma un useragent atributo y extrae el sistema operativo, navegador, dispositivo y otros datos del usuario. Cuando esté configurado, se producen los siguientes atributos:
Nota: Si tus registros contienen user-agents codificados (por ejemplo, registros de IIS), configura este procesador para decodificar la URL antes de analizarla.
Define el procesador de user-agent en la página Pipelines:
{"type":"user-agent-parser","name":"Parses <SOURCE_ATTRIBUTE> to extract all its User-Agent information","is_enabled":true,"sources":["http.useragent"],"target":"http.useragent_details","is_encoded":false}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Predeterminado: false.
sources
Array de cadenas
No
Array de atributos de fuente. Predeterminado: http.useragent.
target
Cadena
Sí
Nombre del atributo padre que contiene todos los detalles extraídos del sources. Predeterminado: http.useragent_details.
is_encoded
Booleano
No
Define si el atributo de fuente está codificado en URL o no. Predeterminado: false.
Procesador de categorías
Utiliza el procesador de categorías para agregar un nuevo atributo (sin espacios ni caracteres especiales en el nombre del nuevo atributo) a un registro que coincida con una consulta de búsqueda proporcionada. Luego, utiliza categorías para crear grupos para una vista analítica (por ejemplo, grupos de URL, grupos de máquinas, entornos y cubos de tiempo de respuesta).
Notas:
La sintaxis de la consulta es la que se encuentra en la barra de búsqueda de Log Explorer. Esta consulta se puede realizar en cualquier atributo o etiqueta de registro, ya sea una faceta o no. Wildcards también se pueden usar dentro de tu consulta.
Una vez que el registro ha coincidido con una de las consultas del procesador, se detiene. Asegúrate de que estén correctamente ordenados en caso de que un registro pueda coincidir con varias consultas.
Los nombres de las categorías deben ser únicos.
Una vez definidos en el procesador de categorías, puedes mapear categorías al estado del registro utilizando el remapeador de estado del registro.
Define el procesador de categorías en la página de Pipelines. Por ejemplo, para categorizar tus registros de acceso web según el valor del rango de código de estado ("OK" for a response code between 200 and 299, "Notice" for a response code between 300 and 399, ...), agrega este procesador:
{"type":"category-processor","name":"Assign a custom value to the <TARGET_ATTRIBUTE> attribute","is_enabled":true,"categories":[{"filter":{"query":"<QUERY_1>"},"name":"<VALUE_TO_ASSIGN_1>"},{"filter":{"query":"<QUERY_2>"},"name":"<VALUE_TO_ASSIGN_2>"}],"target":"<TARGET_ATTRIBUTE>"}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Boolean
No
Si el procesador está habilitado o no. Predeterminado: false
categories
Array de Objetos
Sí
Array de filtros para coincidir o no con un registro y su correspondiente name para asignar un valor personalizado al registro.
target
Cadena
Sí
Nombre del atributo objetivo cuyo valor está definido por la categoría coincidente.
Procesador aritmético
Utiliza el procesador aritmético para agregar un nuevo atributo (sin espacios ni caracteres especiales en el nombre del nuevo atributo) a un registro con el resultado de la fórmula proporcionada. Esto remapea diferentes atributos de tiempo con diferentes unidades en un solo atributo, o calcula operaciones sobre atributos dentro del mismo registro.
Una fórmula de procesador aritmético puede usar paréntesis y operadores aritméticos básicos: -, +, *, /.
Por defecto, se omite un cálculo si falta un atributo. Seleccione Reemplazar atributo faltante por 0 para llenar automáticamente los valores de atributos faltantes con 0 y asegurar que se realice el cálculo.
Notas:
Un atributo puede aparecer como faltante si no se encuentra en los atributos del registro, o si no se puede convertir a un número.
Al usar el operador -, agrega espacios alrededor de él porque los nombres de atributos como start-time pueden contener guiones. Por ejemplo, la siguiente fórmula debe incluir espacios alrededor del operador -: (end-time - start-time) / 1000.
Si el atributo objetivo ya existe, se sobrescribe con el resultado de la fórmula.
Los resultados se redondean hasta la novena decimal. Por ejemplo, si el resultado de la fórmula es 0.1234567891, el valor real almacenado para el atributo es 0.123456789.
Si necesitas escalar una unidad de medida, utiliza el filtro de escala.
Define el procesador aritmético en la página Pipelines:
Si el procesador está habilitado o no. Predeterminado: false.
expression
Cadena
Sí
Operación aritmética entre uno o más atributos de registro.
target
Cadena
Sí
Nombre del atributo que contiene el resultado de la operación aritmética.
is_replace_missing
Booleano
No
Si true, reemplaza todos los atributos faltantes de expression por 0, false omite la operación si falta un atributo. Predeterminado: false.
Procesador de construcción de cadenas
Utiliza el procesador de construcción de cadenas para agregar un nuevo atributo (sin espacios ni caracteres especiales) a un registro con el resultado de la plantilla proporcionada. Esto permite la agregación de diferentes atributos o cadenas en bruto en un solo atributo.
La plantilla se define tanto por texto en bruto como por bloques con la sintaxis %{attribute_path}.
Notas:
Este procesador solo acepta atributos con valores o un arreglo de valores en el bloque (ver ejemplos en la sección de UI a continuación).
Si un atributo no puede ser utilizado (objeto o arreglo de objetos), se reemplaza por una cadena vacía o se omite toda la operación dependiendo de tu selección.
Si un atributo objetivo ya existe, se sobrescribe con el resultado de la plantilla.
Los resultados de una plantilla no pueden exceder 256 caracteres.
Define el procesador de construcción de cadenas en la página Pipelines:
Con el siguiente registro, utiliza la plantilla Request %{http.method} %{http.url} was answered with response %{http.status_code} para devolver un resultado. Por ejemplo:
Request GET https://app.datadoghq.com/users was answered with response 200
Nota: http es un objeto y no se puede usar en un bloque (%{http} falla), mientras que %{http.method}, %{http.status_code} o %{http.url} devuelven el valor correspondiente. Los bloques se pueden usar en un Array de valores o en un atributo específico dentro de un Array.
Por ejemplo, agregar el bloque %{array_ids} devuelve:
123,456,789
%{array_users} no devuelve nada porque es una lista de objetos. Sin embargo, %{array_users.first_name} devuelve una lista de first_names contenidos en el Array:
Si el procesador está habilitado o no, por defecto es false.
template
Cadena
Sí
Una fórmula con uno o más atributos y texto sin procesar.
target
Cadena
Sí
El nombre del atributo que contiene el resultado de la plantilla.
is_replace_missing
Booleano
No
Si true, reemplaza todos los atributos faltantes de template por una cadena vacía. Si false, omite la operación para atributos faltantes. Por defecto: false.
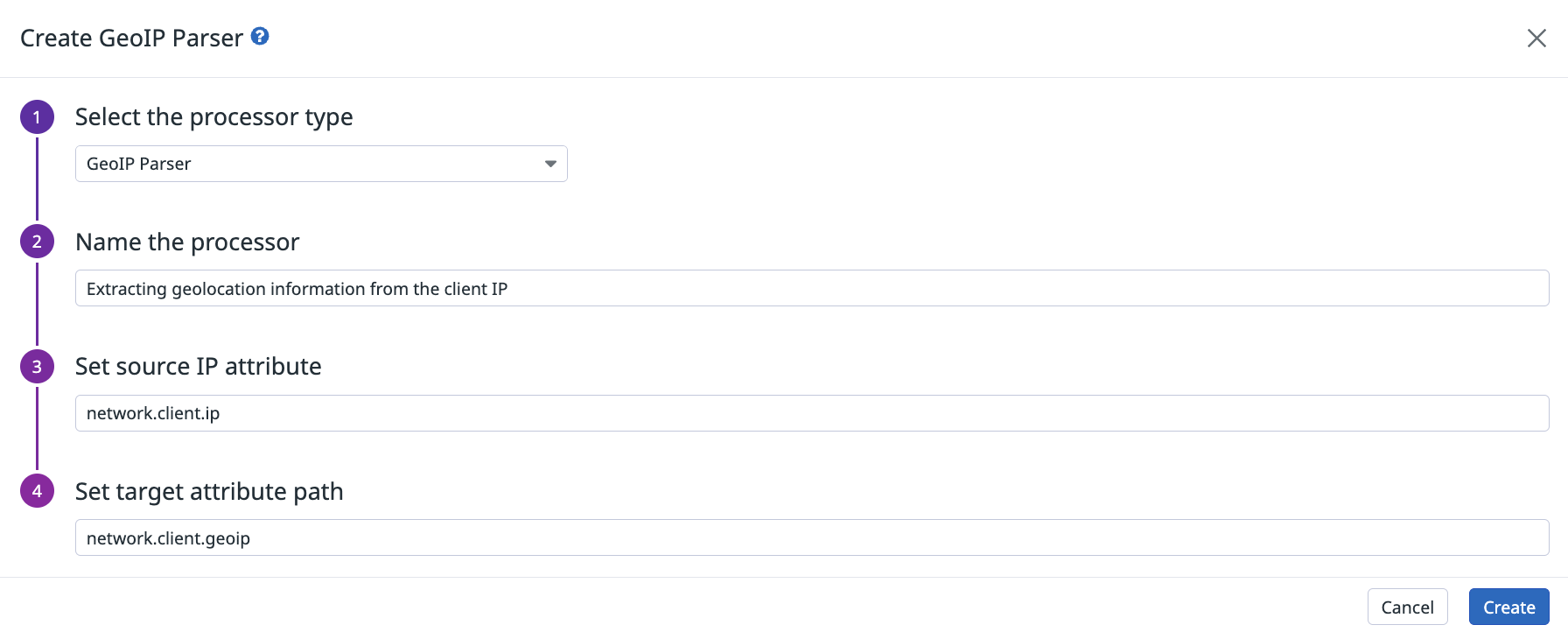
Analizador GeoIP
El analizador geoIP toma un atributo de dirección IP y extrae información de continente, país, subdivisión o ciudad (si está disponible) en la ruta del atributo de destino.
La mayoría de los elementos contienen un atributo name y iso_code (o code para continente). subdivision es el primer nivel de subdivisión que utiliza el país, como “Estados” para los Estados Unidos o “Departamentos” para Francia.
Por ejemplo, el analizador geoIP extrae la ubicación del atributo network.client.ip y la almacena en el atributo network.client.geoip:
{"type":"geo-ip-parser","name":"Parse the geolocation elements from network.client.ip attribute.","is_enabled":true,"sources":["network.client.ip"],"target":"network.client.geoip"}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado o no. Por defecto: false.
sources
Array de cadenas
No
Array de atributos de fuente. Por defecto: network.client.ip.
target
Cadena
Sí
Nombre del atributo padre que contiene todos los detalles extraídos del sources. Por defecto: network.client.geoip.
Procesador de búsqueda
Utilice el procesador de búsqueda para definir un mapeo entre un atributo de registro y un valor legible por humanos guardado en una Tabla de Referencia o en la tabla de mapeo de procesadores.
Por ejemplo, puede usar el procesador de búsqueda para mapear un ID de servicio interno a un nombre de servicio legible por humanos. Alternativamente, puede usarlo para verificar si la dirección MAC que acaba de intentar conectarse al entorno de producción pertenece a su lista de máquinas robadas.
El procesador de búsqueda realiza las siguientes acciones:
Verifica si el registro actual contiene el atributo de fuente.
Verifica si el valor del atributo de fuente existe en la tabla de mapeo.
Si lo hace, crea el atributo de destino con el valor correspondiente en la tabla.
Opcionalmente, si no encuentra el valor en la tabla de mapeo, crea un atributo de destino con el valor por defecto establecido en el campo fallbackValue. Puede ingresar manualmente una lista de pares source_key,target_value o cargar un archivo CSV en la pestaña Manual Mapping.
The size limit for the mapping table is 100Kb. This limit applies across all Lookup Processors on the platform. However, Reference Tables support larger file sizes.
Opcionalmente, si no encuentra el valor en la tabla de mapeo, crea un atributo de destino con el valor de la tabla de referencia. Puede seleccionar un valor para una Reference Table en la pestaña Reference Table.
Si el procesador está habilitado o no. Por defecto: false.
source
Cadena
Sí
Atributo de fuente utilizado para realizar la búsqueda.
target
Cadena
Sí
Nombre del atributo que contiene el valor correspondiente en la lista de mapeo o el default_lookup si no se encuentra en la lista de mapeo.
lookup_table
Array de cadenas
Sí
Tabla de mapeo de valores para el atributo de origen y sus valores de atributo de destino asociados, formateados como [ “source_key1,target_value1”, “source_key2,target_value2” ].
default_lookup
Cadena
No
Valor para establecer el atributo de destino si el valor de origen no se encuentra en la lista.
Remapeador de trazas
Hay dos formas de definir la correlación entre trazas de aplicación y registros:
Utilice el procesador remapeador de trazas para definir un atributo de registro como su ID de traza asociado.
Defina el procesador remapeador de trazas en la página Pipelines. Ingrese la ruta del atributo de ID de traza en el cuadro del procesador de la siguiente manera:
Utilice el procesador remapeador de tramo para definir un atributo de registro como su ID de tramo asociado.
Defina el procesador remapeador de tramo en la página de Pipelines. Ingrese la ruta del atributo del ID de tramo en el cuadro del procesador de la siguiente manera:
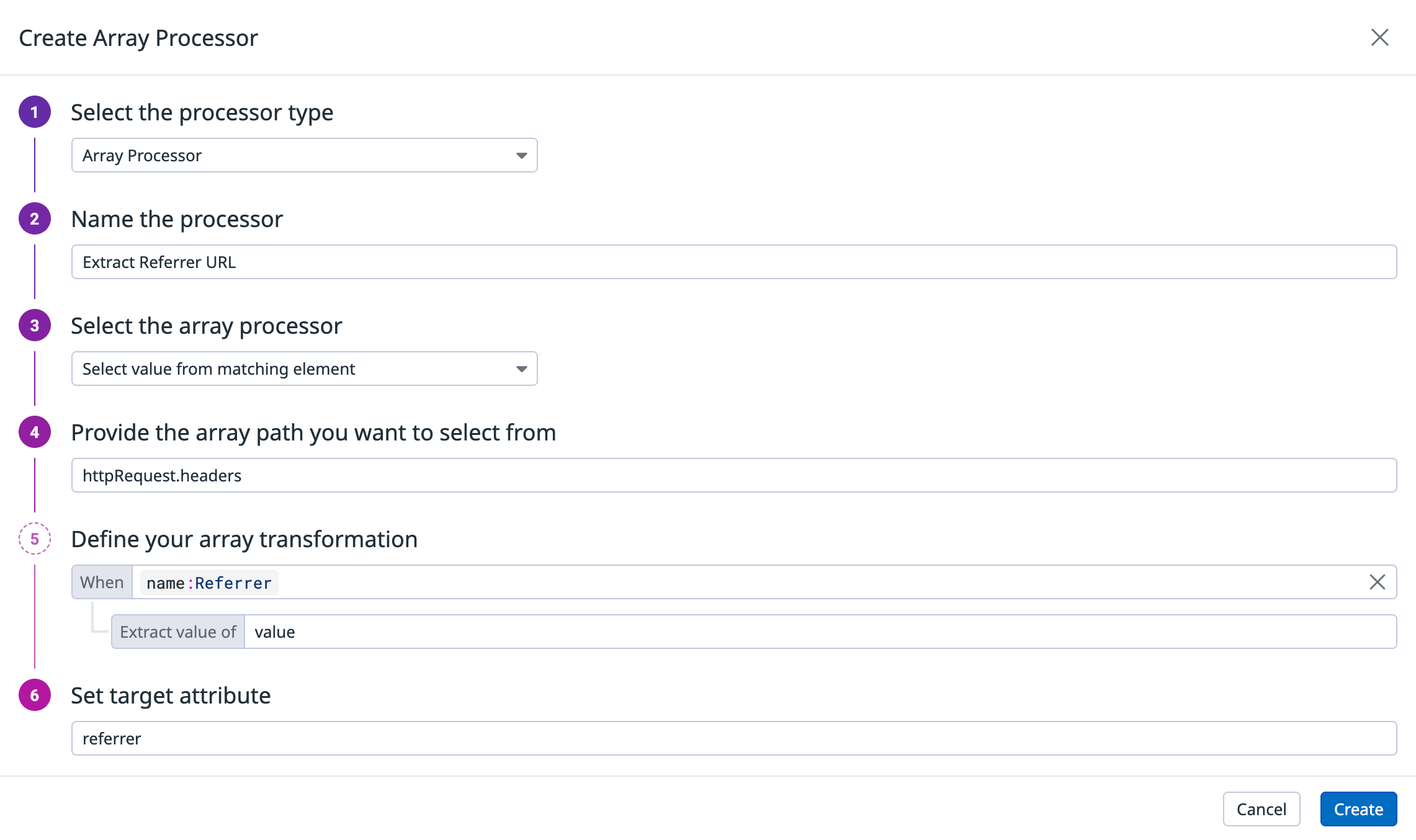
{"type":"array-processor","name":"Append client IP to sourceIps","is_enabled":true,"operation":{"type":"append","source":"network.client.ip","target":"sourceIps"}}
Parámetro
Tipo
Requerido
Descripción
type
Cadena
Sí
Tipo del procesador.
name
Cadena
No
Nombre del procesador.
is_enabled
Booleano
No
Si el procesador está habilitado. Predeterminado: false.
operation.type
Cadena
Sí
Tipo de operación del procesador de arreglos.
operation.source
Cadena
Sí
Atributo a agregar.
operation.target
Cadena
Sí
Atributo de arreglo al que se agregará.
operation.preserve_source
Booleano
No
Si se debe preservar la fuente original después del remapeo. Predeterminado: false.
Procesador decodificador
El procesador decodificador traduce campos de cadenas codificadas en binario a texto (como Base64 o Hex/Base16) a su representación original. Esto permite que los datos sean interpretados en su contexto nativo, ya sea como una cadena UTF-8, un comando ASCII o un valor numérico (por ejemplo, un entero derivado de una cadena hexadecimal). El procesador decodificador es especialmente útil para analizar comandos codificados, registros de sistemas específicos o técnicas de evasión utilizadas por actores de amenazas.
Notas:
Cadenas truncadas: El procesador maneja cadenas Base64/Base16 parcialmente truncadas de manera adecuada, recortando o completando según sea necesario.
Formato hexadecimal: La entrada hexadecimal puede ser decodificada en una cadena (UTF-8) o en un entero.
Manejo de fallos: Si la decodificación falla (debido a una entrada no válida), el procesador omite la transformación y el registro permanece sin cambios.
Establecer el atributo de fuente: Proporcione la ruta del atributo que contiene la cadena codificada, como encoded.base64.
Seleccionar la codificación de fuente: Elija la codificación de binario a texto de la fuente: base64 o base16/hex.
Para Base16/Hex: Elija el formato de salida: string (UTF-8) o integer.
Establezca el atributo de destino: Ingrese la ruta del atributo para almacenar el resultado decodificado.
Procesador de inteligencia de amenazas
Agregue el Procesador de Inteligencia de Amenazas para evaluar los registros contra la tabla utilizando una clave específica de Indicador de Compromiso (IoC), como una dirección IP. Si se encuentra una coincidencia, el registro se enriquece con los atributos relevantes de Inteligencia de Amenazas (TI) de la tabla, lo que mejora la detección, investigación y respuesta.
Utilice el procesador OCSF para normalizar sus registros de seguridad de acuerdo con el Marco de Esquema de Ciberseguridad Abierto (OCSF). El procesador OCSF le permite crear mapeos personalizados que reasignan los atributos de sus registros a las clases de esquema OCSF y sus atributos correspondientes, incluidos los atributos enumerados (ENUM).
El procesador le permite:
Mapear atributos de registros de fuente a atributos de destino OCSF
Configurar atributos ENUM con valores numéricos específicos
Crear subcanalizaciones para diferentes clases de eventos de destino OCSF
Preprocesar registros antes del remapeo OCSF
Para instrucciones detalladas de configuración, ejemplos de configuración y orientación para solucionar problemas, consulte OCSF Processor.