Versión de la integración1.0.0
Data Jobs Monitoring te ayuda a observar, solucionar problemas y optimizar los costes de tus trabajos y clústeres de Databricks.
Esta página se limita a la documentación para la ingesta de métricas de servicio del modelo de Databricks, datos de utilización del clúster y tablas de referencia.
Dashboard de Databricks por defecto
Datadog ofrece varias capacidades de monitorización de Databricks.
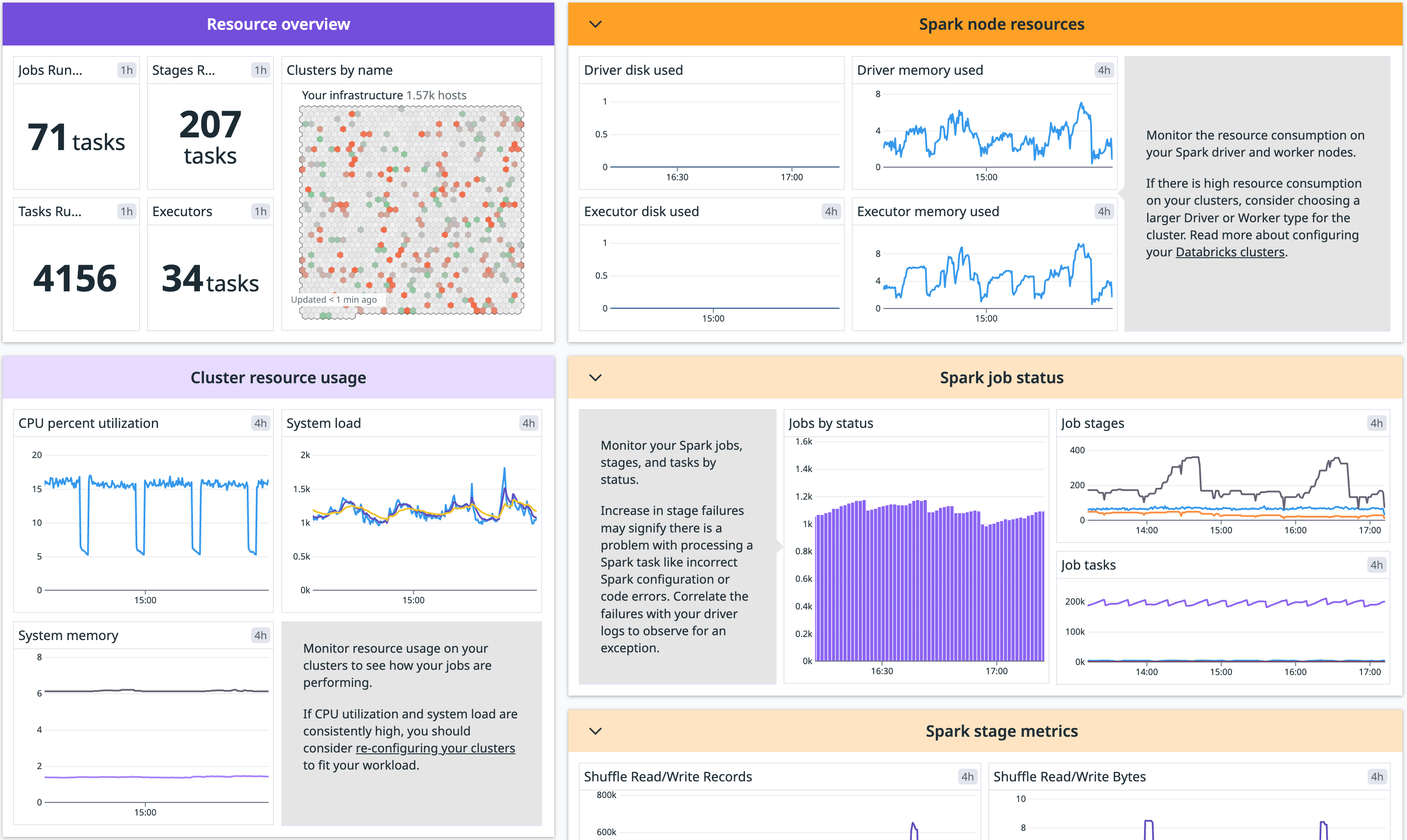
Data Jobs Monitoring proporciona monitorización para tus trabajos y clústeres de Databricks. Puedes detectar trabajos y flujos de trabajo de Databricks problemáticos en cualquier punto de tus pipelines de datos, corregir trabajos fallidos y de larga ejecución con mayor rapidez y optimizar los recursos de clúster para reducir costes.
Cloud Cost Management te ofrece una vista para analizar todos tus costes de DBU de Databricks junto con el gasto en la nube asociado.
Log Management te permite agregar y analizar logs de tus trabajos y clústeres de Databricks. Puedes recopilar estos logs como parte de Data Jobs Monitoring.
Infrastructure Monitoring te ofrece un subconjunto limitado de la funcionalidad de Data Jobs Monitoring: visibilidad de la utilización de recursos de tus clústeres de Databricks y métricas de rendimiento de Apache Spark.
Las Tablas de referencia te permiten importar metadatos de tu espacio de trabajo de Databricks a Datadog. Estas tablas mejoran tu telemetría de Datadog con contexto crítico como nombres de espacios de trabajo, definiciones de trabajo, configuraciones de clúster y roles de usuario.
Las métricas de servicio de modelos brindan información sobre el rendimiento de la infraestructura de servicio de modelos de Databricks. Con estas métricas, puedes detectar endpoints que tienen una tasa de errores alta, una latencia alta, un aprovisionamiento excesivo o insuficiente, entre otros.
Configuración
Instalación
Obtén información sobre el estado de tu infraestructura que sirve a modelos siguiendo las instrucciones de configuración que sirve a modelos.
Monitoriza aplicaciones de Databricks Spark con la integración de Datadog Spark. Instala el Datadog Agent en tus clústeres siguiendo las instrucciones de configuración para tu clúster apropiado. Consulta las instrucciones de configuración de Spark.
Configuración
Configuración que sirve al modelo
Los nuevos espacios de trabajo deben autenticarse mediante OAuth. Los espacios de trabajo integrados con un token de acceso personal siguen funcionando y pueden cambiar a OAuth en cualquier momento. Después de que un espacio de trabajo empiece a utilizar OAuth, no podrá volver a un token de acceso personal.
- En tu cuenta de Databricks, haz clic en User Management (Gestión de usuarios) en el menú de la izquierda. A continuación, en la pestaña Service principals (Entidades principales de servicio), haz clic en Add service principal (Añadir entidad principal de servicio).
- En la pestaña Credentials & secrets (Credenciales y secretos), haz clic en Generate secret (Generar secreto). Establece Lifetime (days) (Vida útil (días)) en el valor máximo permitido (730) y, a continuación, haz clic en Generate (Generar). Anota tu ID de cliente y tu secreto de cliente. Anota también el ID de tu cuenta, que puedes encontrar haciendo clic en tu perfil en la esquina superior derecha.
- Haz clic en Workspaces (Espacios de trabajo) en el menú de la izquierda y, a continuación, selecciona el nombre de tu espacio de trabajo.
- Ve a la pestaña Permissions (Permisos) y haz clic en Add permissions (Añadir permisos).
- Busca la entidad principal de servicio que has creado y asígnale el permiso Admin.
- En Datadog, abre el cuadro de la integración Databricks.
- En la pestaña Configurar, haz clic en Add Databricks Workspace (Añadir espacio de trabajo de Databricks).
- Introduce un nombre de espacio de trabajo, la URL de tu espacio de trabajo de Databricks, el ID de cuenta y el ID y secreto de cliente que has generado.
- En la sección Seleccionar recursos para configurar la colección, asegúrate de que Métricas - Al servicio del modelo está Habilitado.
Esta opción sólo está disponible para espacios de trabajo creados antes del 7 de julio de 2025. Los nuevos espacios de trabajo deben autenticarse mediante OAuth.
En tu espacio de trabajo de Databricks, haz clic en tu perfil en la esquina superior derecha y ve a Configuración. Selecciona Desarrollador en la barra lateral izquierda. Junto a Tokens de acceso, haz clic en Manage (Gestionar).
Haz clic en Generate new token (Generar nuevo token), introduce “Datadog Integration” en el campo Comentario, elimina el valor predeterminado en Vida útil (días) y haz clic en Generate (Generar). Toma nota de tu token.
Importante:
- Asegúrate de borrar el valor por defecto en Vida útil (días) para que el token no caduque y no se rompa la integración.
- Asegúrate de que la cuenta que genera el token tiene acceso CAN VIEW para los trabajos y clústeres de Databricks que deseas monitorizar.
Como alternativa, sigue la documentación oficial de Databricks para generar un token de acceso para una entidad principal de servicio.
En Datadog, abre el cuadro de la integración Databricks.
En la pestaña Configurar, haz clic en Add Databricks Workspace (Añadir espacio de trabajo de Databricks).
Introduce un nombre de espacio de trabajo, la URL de tu espacio de trabajo de Databricks y el token de Databricks que generaste.
En la sección Seleccionar recursos para configurar la colección, asegúrate de que Métricas - Al servicio del modelo está Habilitado.
Configuración de la tabla de referencia
- Configura un espacio de trabajo en el cuadro de integración de Databricks de Datadog.
- En el panel de detalle de las cuentas, haz clic en Reference Tables (Tablas de referencia).
- En la pestaña Reference Tables (Tablas de referencia), haz clic en Add New Reference Table (Añadir nueva tabla de referencia).
- Proporciona el nombre de la tabla de referencia, el nombre de la tabla de Databricks y la clave principal de tu vista o tabla de Databricks.
- Para obtener resultados óptimos, crea una vista en Databricks que incluya únicamente los datos específicos que deseas enviar a Datadog. Esto significa generar una tabla dedicada que refleje el ámbito exacto necesario para tu caso de uso.
- Haz clic en Save (Guardar).
Configuración de Spark
Configura la integración de Spark para monitorizar tu clúster de Apache Spark en Databricks y recopilar el sistema y las métricas de Spark.
Cada script descrito a continuación puede modificarse para adaptarlo a tus necesidades. Por ejemplo, puedes:
- Añadir etiquetas (tags) específicas a tus instancias.
- Modificar la configuración de la integración de Spark.
También puedes definir o modificar variables de entorno con la ruta del script init en el ámbito del clúster utilizando la interfaz de usuario, la CLI de Databricks o invocando la API de clústeres:
- Configura
DD_API_KEY para identificar mejor tus clústeres. - Configura
DD_ENV para identificar mejor tus clústeres. - Configura
DD_SITE en tu sitio: datadoghq.com
Por razones de seguridad, no se recomienda definir la variable de entorno `DD_API_KEY` en texto simple directamente en la interfaz de usuario. En su lugar, utiliza
secretos de Databricks.
Con un script de inicio global
Un script init global se ejecuta en cada clúster creado en tu área de trabajo. Los scripts init globales son útiles cuando se desea aplicar configuraciones de bibliotecas o pantallas de seguridad en toda la organización.
Solo los administradores del área de trabajo pueden gestionar scripts de inicio globales.
Los scripts de inicio globales solo se ejecutan en clústeres configurados con un único usuario o en el modo de acceso compartido sin aislamiento de legacy. Por lo tanto, Databricks recomienda configurar todos los scripts de inicio como ámbito de clúster y gestionarlos en toda el área de trabajo mediante políticas de clúster.
Utiliza la interfaz de usuario de Databricks para editar los scripts de inicio globales:
- Elige uno de los siguientes scripts para instalar el Agent en el controlador o en los nodos controlador y trabajador del clúster.
- Modifica el script para adaptarlo a tus necesidades. Por ejemplo, puedes añadir etiquetas (tags) o definir una configuración específica para la integración.
- Ve a la configuración de administración y haz clic en la pestaña Scripts de inicio globales.
- Haz clic en el botón + Añadir.
- Dale un nombre al script, por ejemplo
Datadog init script y pégalo en el campo Script. - Haz clic en el conmutador Habilitado para activarlo.
- Haz clic en el botón Añadir.
Después de estos pasos, cualquier clúster nuevo utiliza el script automáticamente. Puedes encontrar más información sobre scripts init globales en la documentación oficial de Databricks.
Puedes definir varios scripts de inicio y especificar su orden en la interfaz de usuario.
Instala el Datadog Agent en el controlador
Instala el Datadog Agent en el nodo controlador del clúster.
Es necesario definir el valor de la variable `DD_API_KEY` en el script.
``script de shell
#!/bin/bash
cat «EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco “Running on the driver? $DB_IS_DRIVER”
eco “Driver ip: $DB_DRIVER_IP”
DB_CLUSTER_NAME=$(echo “$DB_CLUSTER_NAME” | sed -e ’s/ //g’ -e “s/’//g”)
DD_API_KEY=’<YOUR_API_KEY>'
si [[ ${DB_IS_DRIVER} = “TRUE” ]]; entonces
eco “Installing Datadog Agent on the driver…”
DD_TAGS=“entorno:${DD_ENV}”,“databricks_cluster_id:${DB_CLUSTER_ID}”,“databricks_cluster_name:${DB_CLUSTER_NAME}”,“spark_host_ip:${DB_DRIVER_IP}”,“spark_node:driver”,“databricks_instance_type:${DB_INSTANCE_TYPE}”,“databricks_is_job_cluster:${DB_IS_JOB_CLUSTER}”
INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true
DD_API_KEY=$DD_API_KEY
DD_HOST_TAGS=$DD_TAGS
DD_HOSTNAME="$(hostname | xargs)"
DD_SITE="${DD_SITE:-datadoghq.com}"
bash -c “$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
Evitar conflictos en el puerto 6062
eco “process_config.expvar_port: 6063” » /etc/datadog-agent/datadog.yaml
eco “Datadog Agent is installed”
si bien[ -z $DB_DRIVER_PORT ]; haz
si [ -e “/tmp/driver-env.sh” ]; entonces
DB_DRIVER_PORT=”$(grep -i “CONF_UI_PORT” /tmp/driver-env.sh | cut -d’=’ -f2)"
fi
eco “Waiting 2 seconds for DB_DRIVER_PORT”
sleep 2
hecho
eco “DB_DRIVER_PORT=$DB_DRIVER_PORT”
ESCRIBIR ARCHIVO DE CONFIGURACIÓN DE INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco “init_config:
instancias:
- spark_url: http://${DB_DRIVER_IP}:${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: ${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/Logs/.log
fuente: spark
servicio: databricks
log_processing_rules:
- tipo: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[-/]\d{2,4}[-/]\d{2,4}.” > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco “Spark integration configured”
ACTIVAR LOGS EN Datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i ‘/.logs_enabled:./a logs_enabled: true’ /etc/datadog-agent/datadog.yaml
fi
eco “Restart the agent”
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh » /tmp/datadog_start.log 2>&1 & disown
Install the Datadog Agent on driver and worker nodes
Install the Datadog Agent on the driver and worker nodes of the cluster.
You will need to define the value of the `DD_API_KEY` variable inside the script.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
DD_API_KEY='<YOUR_API_KEY>'
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# CONFIGURE HOST TAGS FOR WORKERS
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
# CONFIGURE HOSTNAME EXPLICITLY IN datadog.yaml TO PREVENT AGENT FROM FAILING ON VERSION 7.40+
# SEE https://github.com/DataDog/datadog-agent/issues/14152 FOR CHANGE
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Con un script init en el clúster
Los scripts de inicio de ámbito de clúster son scripts de inicio definidos en la configuración del clúster. Los scripts de inicio de ámbito de clúster se aplican a los clústeres que creas y a los creados para ejecutar trabajos. Databricks admite la configuración y el almacenamiento de scripts de inicio a través de:
- Archivos de área de trabajo
- Unity Catalog Volumes
- Almacenamiento de objetos en la nube
Utiliza la interfaz de usuario de Databricks para editar el clúster y ejecutar el script de inicio:
- Elige uno de los siguientes scripts para instalar el Agent en el controlador o en los nodos controlador y trabajador del clúster.
- Modifica el script para adaptarlo a tus necesidades. Por ejemplo, puedes añadir etiquetas (tags) o definir una configuración específica para la integración.
- Guarda el script en tu área de trabajo con el menú Área de trabajo de la izquierda. Si utilizas Unity Catalog Volume, guarda el script en tu Volume con el menú Catalog de la izquierda.
- En la página de configuración del clúster, haz clic en el conmutador de opciones Avanzadas.
- En las Variables de entorno, especifica la variable de entorno
DD_API_KEY y, opcionalmente, las variables de entorno DD_ENV y DD_SITE. - Ve a la pestaña Scripts de inicio.
- En el menú desplegable Destino, selecciona el tipo de destino
Workspace. Si utilizas Unity Catalog Volume, en el menú desplegable Destino, selecciona el tipo de destino Volume. - Especifica una ruta al script init.
- Haz clic en el botón Añadir.
Si guardaste tu datadog_init_script.sh directamente en el área de trabajo Shared, puedes acceder al archivo en la siguiente ruta: /Shared/datadog_init_script.sh.
Si guardaste tu datadog_init_script.sh directamente en un área de trabajo del usuario, puedes acceder al archivo en la siguiente ruta: /Users/$EMAIL_ADDRESS/datadog_init_script.sh.
Si guardaste tu datadog_init_script.sh directamente en un Unity Catalog Volume, puedes acceder al archivo en la siguiente ruta: /Volumes/$VOLUME_PATH/datadog_init_script.sh.
Puedes encontrar más información sobre los scripts init de clúster en la documentación oficial de Databricks.
Instala el Datadog Agent en el controlador
Instala el Datadog Agent en el nodo controlador del clúster.
``script de shell
#!/bin/bash
cat «EOF > /tmp/start_datadog.sh
#!/bin/bash
fecha -u +"%Y-%m-%d %H:%M:%S UTC"
eco “Running on the driver? $DB_IS_DRIVER”
eco “Driver ip: $DB_DRIVER_IP”
DB_CLUSTER_NAME=$(echo “$DB_CLUSTER_NAME” | sed -e ’s/ //g’ -e “s/’//g”)
si [[ ${DB_IS_DRIVER} = “TRUE” ]]; entonces
eco “Installing Datadog Agent on the driver…”
DD_TAGS=“entorno:${DD_ENV}”,“databricks_cluster_id:${DB_CLUSTER_ID}”,“databricks_cluster_name:${DB_CLUSTER_NAME}”,“spark_host_ip:${DB_DRIVER_IP}”,“spark_node:driver”,“databricks_instance_type:${DB_INSTANCE_TYPE}”,“databricks_is_job_cluster:${DB_IS_JOB_CLUSTER}”
INSTALAR LA ÚLTIMA VERSIÓN DEL DATADOG AGENT 7 EN LOS NODOS CONTROLADOR Y TRABAJADOR
DD_INSTALL_ONLY=true
DD_API_KEY=$DD_API_KEY
DD_HOST_TAGS=$DD_TAGS
DD_HOSTNAME="$(hostname | xargs)"
DD_SITE="${DD_SITE:-datadoghq.com}"
bash -c “$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
Evitar conflictos en el puerto 6062
eco “process_config.expvar_port: 6063” » /etc/datadog-agent/datadog.yaml
eco “Datadog Agent is installed”
si bien[ -z $DB_DRIVER_PORT ]; haz
si [ -e “/tmp/driver-env.sh” ]; entonces
DB_DRIVER_PORT=”$(grep -i “CONF_UI_PORT” /tmp/driver-env.sh | cut -d’=’ -f2)"
fi
eco “Waiting 2 seconds for DB_DRIVER_PORT”
sleep 2
hecho
eco “DB_DRIVER_PORT=$DB_DRIVER_PORT”
ESCRIBIR ARCHIVO DE CONFIGURACIÓN DE INTEGRACIÓN DE SPARK CON MÉTRICAS DE STREAMING ESTRUCTURADAS ACTIVADAS
MODIFICAR PARA INCLUIR OTRAS OPCIONES EN spark.d/conf.yaml.example
eco “init_config:
instancias:
- spark_url: http://${DB_DRIVER_IP}:${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: ${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- tipo: archivo
ruta: /databricks/driver/Logs/.log
fuente: spark
servicio: databricks
log_processing_rules:
- tipo: multi_line
nombre: new_log_start_with_date
patrón: \d{2,4}[-/]\d{2,4}[-/]\d{2,4}.” > /etc/datadog-agent/conf.d/spark.d/spark.yaml
eco “Spark integration configured”
ACTIVAR LOGS EN Datadog.yaml PARA RECOPILAR LOGS DEL CONTROLADOR
sed -i ‘/.logs_enabled:./a logs_enabled: true’ /etc/datadog-agent/datadog.yaml
fi
eco “Restart the agent”
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh » /tmp/datadog_start.log 2>&1 & disown
Install the Datadog Agent on driver and worker nodes
Install the Datadog Agent on the driver and worker nodes of the cluster.
#!/bin/bash
cat <<EOF > /tmp/start_datadog.sh
#!/bin/bash
date -u +"%Y-%m-%d %H:%M:%S UTC"
echo "Running on the driver? \$DB_IS_DRIVER"
echo "Driver ip: \$DB_DRIVER_IP"
DB_CLUSTER_NAME=$(echo "$DB_CLUSTER_NAME" | sed -e 's/ /_/g' -e "s/'/_/g")
if [[ \${DB_IS_DRIVER} = "TRUE" ]]; then
echo "Installing Datadog Agent on the driver (master node)."
# CONFIGURE HOST TAGS FOR DRIVER
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${DB_DRIVER_IP}","spark_node:driver","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
DD_INSTALL_ONLY=true \
DD_API_KEY=\$DD_API_KEY \
DD_HOST_TAGS=\$DD_TAGS \
DD_HOSTNAME="\$(hostname | xargs)" \
DD_SITE="\${DD_SITE:-datadoghq.com}" \
bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
while [ -z \$DB_DRIVER_PORT ]; do
if [ -e "/tmp/driver-env.sh" ]; then
DB_DRIVER_PORT="\$(grep -i "CONF_UI_PORT" /tmp/driver-env.sh | cut -d'=' -f2)"
fi
echo "Waiting 2 seconds for DB_DRIVER_PORT"
sleep 2
done
echo "DB_DRIVER_PORT=\$DB_DRIVER_PORT"
# WRITING CONFIG FILE FOR SPARK INTEGRATION WITH STRUCTURED STREAMING METRICS ENABLED
# MODIFY TO INCLUDE OTHER OPTIONS IN spark.d/conf.yaml.example
echo "init_config:
instances:
- spark_url: http://\${DB_DRIVER_IP}:\${DB_DRIVER_PORT}
spark_cluster_mode: spark_driver_mode
cluster_name: \${DB_CLUSTER_NAME}
streaming_metrics: true
executor_level_metrics: true
logs:
- type: file
path: /databricks/driver/logs/*.log
source: spark
service: databricks
log_processing_rules:
- type: multi_line
name: new_log_start_with_date
pattern: \d{2,4}[\-\/]\d{2,4}[\-\/]\d{2,4}.*" > /etc/datadog-agent/conf.d/spark.d/spark.yaml
echo "Spark integration configured"
# ENABLE LOGS IN datadog.yaml TO COLLECT DRIVER LOGS
sed -i '/.*logs_enabled:.*/a logs_enabled: true' /etc/datadog-agent/datadog.yaml
else
echo "Installing Datadog Agent on the worker."
# CONFIGURE HOST TAGS FOR WORKERS
DD_TAGS="environment:\${DD_ENV}","databricks_cluster_id:\${DB_CLUSTER_ID}","databricks_cluster_name:\${DB_CLUSTER_NAME}","spark_host_ip:\${SPARK_LOCAL_IP}","spark_node:worker","databricks_instance_type:\${DB_INSTANCE_TYPE}","databricks_is_job_cluster:\${DB_IS_JOB_CLUSTER}"
# INSTALL THE LATEST DATADOG AGENT 7 ON DRIVER AND WORKER NODES
# CONFIGURE HOSTNAME EXPLICITLY IN datadog.yaml TO PREVENT AGENT FROM FAILING ON VERSION 7.40+
# SEE https://github.com/DataDog/datadog-agent/issues/14152 FOR CHANGE
DD_INSTALL_ONLY=true DD_API_KEY=\$DD_API_KEY DD_HOST_TAGS=\$DD_TAGS DD_HOSTNAME="\$(hostname | xargs)" bash -c "\$(curl -L https://s3.amazonaws.com/dd-agent/scripts/install_script_agent7.sh)"
echo "Datadog Agent is installed"
fi
# Avoid conflicts on port 6062
echo "process_config.expvar_port: 6063" >> /etc/datadog-agent/datadog.yaml
echo "Restart the agent"
sudo service datadog-agent restart
EOF
chmod a+x /tmp/start_datadog.sh
/tmp/start_datadog.sh >> /tmp/datadog_start.log 2>&1 & disown
Datos recopilados
Métricas
| |
|---|
databricks.model_serving.cpu_usage_percentage
(gauge) | Uso medio de la CPU utilizada en todas las réplicas durante el último minuto
Se muestra como porcentaje |
databricks.model_serving.gpu_mem_usage_percentage.avg
(gauge) | Uso medio de memoria de GPU utilizado en todas las GPU durante el minuto
Se muestra como porcentaje |
databricks.model_serving.gpu_mem_usage_percentage.max
(gauge) | Uso máximo de memoria de GPU utilizado en todas las GPU durante el minuto
Se muestra como porcentaje. |
databricks.model_serving.gpu_mem_usage_percentage.min
(gauge) | Uso mínimo de memoria de GPU utilizado en todas las GPU durante el minuto
Se muestra como porcentaje |
databricks.model_serving.gpu_usage_percentage.avg
(gauge) | Uso medio de la GPU utilizada en todas las GPU durante el minuto
Se muestra como porcentaje. |
databricks.model_serving.gpu_usage_percentage.max
(gauge) | Uso máximo de la GPU utilizado en todas las GPU durante el minuto
Se muestra como porcentaje |
databricks.model_serving.gpu_usage_percentage.min
(gauge) | Uso mínimo de la GPU utilizado en todas las GPU durante el minuto
Se muestra como porcentaje |
databricks.model_serving.mem_usage_percentage
(gauge) | Uso medio de la memoria utilizada en todas las réplicas durante el último minuto
Se muestra como porcentaje |
databricks.model_serving.provisioned_concurrent_requests_total
(gauge) | Número de concurrencias provisionadas durante el último minuto
Se muestra como solicitud |
databricks.model_serving.request_4xx_count_total
(gauge) | Número de errores 4xx durante el último minuto
Se muestra como solicitud |
databricks.model_serving.request_5xx_count_total
(gauge) | Número de errores 5xx durante el último minuto
Se muestra como solicitud |
databricks.model_serving.request_count_total
(gauge) | Número de solicitudes durante el último minuto
Se muestra como solicitud |
databricks.model_serving.request_latency_ms.75percentile
(gauge) | Percentil 75 de latencia de solicitud en milisegundos durante el minuto
Se muestra en milisegundos |
databricks.model_serving.request_latency_ms.90percentile
(gauge) | Percentil 90 de latencia de solicitud en milisegundos durante el minuto
Se muestra en milisegundos |
databricks.model_serving.request_latency_ms.95percentile
(gauge) | Percentil 95 de latencia de solicitud en milisegundos durante el minuto
Se muestra en milisegundos |
databricks.model_serving.request_latency_ms.99percentile
(gauge) | Percentil 99 de latencia de solicitud en milisegundos durante el minuto
Se muestra en milisegundos |
Métricas de servicio del modelo
Consulta metadata.csv para obtener una lista de las métricas proporcionadas por esta integración.
Métricas de Spark
Consulta la documentación de la integración de Spark para obtener una lista de las métricas de Spark recopiladas.
Checks de servicio
Consulta la documentación de la integración de Spark para ver la lista de checks de servicio recopilados.
Eventos
La integración de Databricks no incluye ningún evento.
Solucionar problemas
Puedes solucionar los problemas habilitando el terminal web de Databricks o utilizando un notebook de Databricks. Consulta la documentación Solución de problemas del Agent para obtener información sobre pasos útiles para la resolución de problemas.
¿Necesitas ayuda? Ponte en contacto con el soporte de Datadog.
Referencias adicionales
Documentación útil adicional, enlaces y artículos:
{kind=link}