Live Processes se encuentra incluido en el plan Enterprise. Para todos los demás planes, ponte en contacto con la persona encargada de tu cuenta o escribe a
success@datadoghq.com a fin de solicitar esta función.
Introducción
Live Processes de Datadog te brinda visibilidad en tiempo real de los procesos que se ejecutan en tu infraestructura. Utiliza Live Processes para:
- Ver todos tus procesos en ejecución en un solo lugar
- Desglosar el consumo de recursos en tus hosts y contenedores a nivel de proceso
- Consultar procesos que se ejecutan en un host específico, en una zona específica o que ejecutan una carga de trabajo específica
- Monitorizar el rendimiento del software interno y de terceros que ejecutas con métricas del sistema con una granularidad de dos segundos
- Añadir contexto a tus dashboards y notebooks
Instalación
Si utilizas el Agent 5, sigue este proceso de instalación específico. Si utilizas el Agent 6 o 7, consulta las instrucciones a continuación.
Una vez instalado el Datadog Agent, habilita la recopilación de Live Processes al editar el archivo de configuración principal del Agent al establecer el siguiente parámetro en true:
process_config:
process_collection:
enabled: true
Además, algunas opciones de configuración se pueden establecer como variables de entorno.
Nota: Las opciones establecidas como variables de entorno anulan las configuraciones definidas en el archivo de configuración.
Una vez que se haya completado la configuración, reinicia el Agent.
Sigue las instrucciones para el Docker Agent, al introducir los siguientes atributos, además de cualquier otro ajuste personalizado que resulte apropiado:
-v /etc/passwd:/etc/passwd:ro
-e DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED=true
Nota:
- Para recopilar información sobre el contenedor en la instalación estándar, el usuario
dd-agent debe tener permisos a fin de acceder a docker.sock. - La ejecución del Agent como contenedor aún te permite recopilar procesos del host.
Actualiza tu archivo datadog-values.yaml con la siguiente configuración de recopilación de procesos:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
Luego, actualiza tu Helm chart:
helm upgrade -f datadog-values.yaml <RELEASE_NAME> datadog/datadog
Nota: La ejecución del Agent como contenedor aún te permite recopilar procesos del host.
En tu datadog-agent.yaml, establece features.liveProcessCollection.enabled en true.
apiVersion: datadoghq.com/v2alpha1
kind: DatadogAgent
metadata:
name: datadog
spec:
global:
credentials:
apiKey: <DATADOG_API_KEY>
features:
liveProcessCollection:
enabled: true
After making your changes, apply the new configuration by using the following command:
kubectl apply -n $DD_NAMESPACE -f datadog-agent.yaml
Nota: La ejecución del Agent como contenedor aún te permite recopilar procesos del host.
En el manifiesto datadog-agent.yaml utilizado para crear el DaemonSet, añade las siguientes variables de entorno, montaje de volumen y volumen:
env:
- name: DD_PROCESS_CONFIG_PROCESS_COLLECTION_ENABLED
value: "true"
volumeMounts:
- name: passwd
mountPath: /etc/passwd
readOnly: true
volumes:
- hostPath:
path: /etc/passwd
name: passwd
Consulta las páginas de información de la Instalación de DaemonSet estándar y el Docker Agent para obtener documentación adicional.
Nota: La ejecución del Agent como contenedor aún te permite recopilar procesos del host.
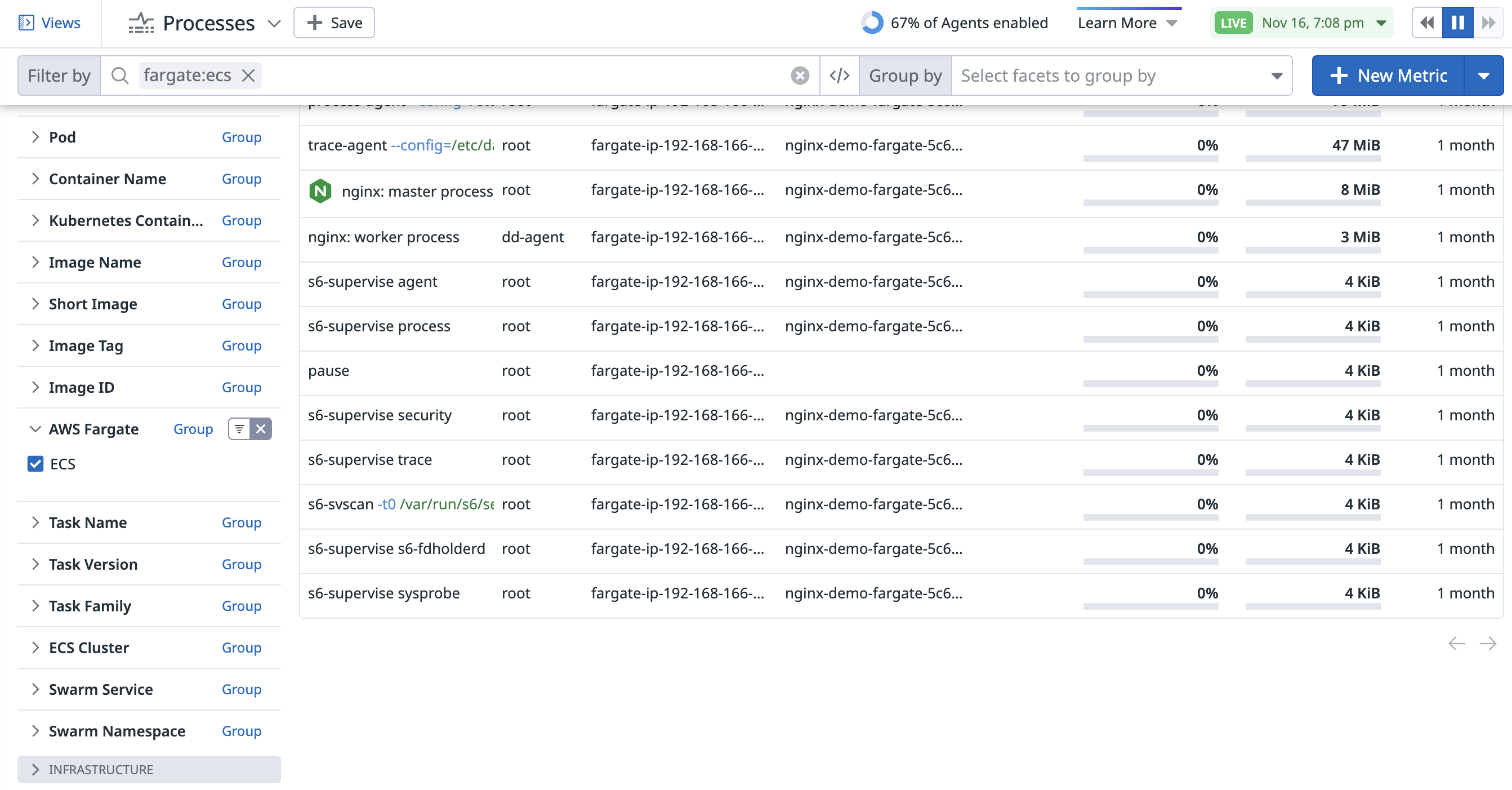
Puedes ver tus procesos de ECS Fargate en Datadog. Para ver su relación con los contenedores de ECS Fargate, utiliza la versión del Datadog Agent 7.50.0 o una posterior.
Para recopilar procesos, el Datadog Agent se debe ejecutar como un contenedor en la tarea.
Para habilitar la monitorización de procesos en ECS Fargate, establece la variable de entorno DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED en true en la definición de contenedor del Datadog Agent en la definición de tarea.
Por ejemplo:
{
"taskDefinitionArn": "...",
"containerDefinitions": [
{
"name": "datadog-agent",
"image": "public.ecr.aws/datadog/agent:latest",
...
"environment": [
{
"name": "DD_PROCESS_AGENT_PROCESS_COLLECTION_ENABLED",
"value": "true"
}
...
]
...
}
]
...
}
Para comenzar a recopilar información sobre el proceso en ECS Fargate, añade el parámetro PidMode a la definición de tarea y establécela en task de la siguiente manera:
Una vez que se haya habilitado, utiliza la faceta de contenedores de AWS Fargate en la página de Live Processes para filtrar procesos por ECS, o ingresa fargate:ecs en la consulta de búsqueda.
Para obtener más información sobre la instalación del Datadog Agent con AWS ECS Fargate, consulta la documentación de la integración de ECS Fargate.
Estadísticas de E/S
El sondeo del sistema de Datadog, que se ejecuta con privilegios elevados, puede recopilar estadísticas de E/S y archivos abiertos. Para habilitar el módulo de proceso del sondeo del sistema, utiliza la siguiente configuración:
Copia la configuración de ejemplo del sondeo del sistema:
sudo -u dd-agent install -m 0640 /etc/datadog-agent/system-probe.yaml.example /etc/datadog-agent/system-probe.yaml
Edita /etc/datadog-agent/system-probe.yaml para habilitar el módulo de proceso:
system_probe_config:
process_config:
enabled: true
Reinicia el Agent:
sudo systemctl restart datadog-agent
Nota: Si el comando systemctl no se encuentra disponible en tu sistema, ejecuta el siguiente comando en su lugar: sudo service datadog-agent restart
Limpieza de argumentos de proceso
Para ocultar datos confidenciales en la página de Live Processes, el Agent limpia los argumentos confidenciales de la línea de comandos del proceso. Esta función se encuentra habilitada de manera predeterminada y cualquier argumento de proceso que coincida con una de las siguientes palabras tiene su valor oculto.
"password", "passwd", "mysql_pwd", "access_token", "auth_token", "api_key", "apikey", "secret", "credentials", "stripetoken"
Nota: La coincidencia no distingue entre mayúsculas y minúsculas.
Define tu propia lista para fusionarla con la predeterminada, con el campo custom_sensitive_words en el archivo datadog.yaml en la sección process_config. Utiliza comodines (*) para definir tu propio contexto coincidente. Sin embargo, no se admite un comodín único ('*') como una palabra confidencial.
process_config:
scrub_args: true
custom_sensitive_words: ['personal_key', '*token', 'sql*', '*pass*d*']
Nota: Las palabras en custom_sensitive_words solo deben tener caracteres alfanuméricos, guiones bajos o comodines ('*'). No se admiten palabras confidenciales que solo contengan comodines.
En la siguiente imagen se muestra un proceso en la página de Live Processes cuyos argumentos se han ocultado con la configuración anterior.
Establece scrub_args en false para deshabilitar por completo la limpieza de argumentos de proceso.
También puedes limpiar todos los argumentos de los procesos al habilitar la marca strip_proc_arguments en tu archivo de configuración datadog.yaml:
process_config:
strip_proc_arguments: true
Puedes utilizar el Helm chart para definir tu propia lista, que se fusiona con la predeterminada. Añade las variables de entorno DD_SCRUB_ARGS y DD_CUSTOM_SENSITIVE_WORDS a tu archivo datadog-values.yaml y actualiza tu Datadog Helm chart:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_SCRUB_ARGS
value: "true"
- name: DD_CUSTOM_SENSITIVE_WORDS
value: "personal_key,*token,*token,sql*,*pass*d*"
Utiliza comodines (*) para definir tu propio contexto coincidente. Sin embargo, no se admite un solo comodín ('*') como palabra confidencial.
Establece DD_SCRUB_ARGS en false para deshabilitar por completo la limpieza de argumentos de proceso.
De manera alternativa, puedes eliminar todos los argumentos de los procesos al habilitar la variable DD_STRIP_PROCESS_ARGS en tu archivo datadog-values.yaml:
datadog:
# (...)
processAgent:
enabled: true
processCollection: true
agents:
containers:
processAgent:
env:
- name: DD_STRIP_PROCESS_ARGS
value: "true"
Consultas
Procesos de contexto
Los procesos son, por naturaleza, objetos de cardinalidad extremadamente alta. Para refinar tu contexto y ver procesos relevantes, puedes utilizar filtros de texto y etiquetas.
Filtros de texto
Cuando ingresas una cadena de texto en la barra de búsqueda, la búsqueda de cadenas difusas se utiliza para consultar procesos que contienen esa cadena de texto en sus líneas de comando o rutas. Ingresa una cadena de dos o más caracteres para ver los resultados. A continuación se muestra el entorno de demostración de Datadog, filtrado con la cadena postgres /9..
Nota: /9. ha coincidido en la ruta del comando, y postgres coincide con el propio comando.
Para combinar varias búsquedas de cadenas en una consulta compleja, utiliza cualquiera de los siguientes operadores booleanos:
AND- Intersección: ambos términos están en los eventos seleccionados (si no se añade nada, se toma AND de manera predeterminada)
Ejemplo: java AND elasticsearch OR- Unión: cualquiera de los términos se encuentra en los eventos seleccionados
Ejemplo: java OR python NOT / !- Exclusión: el siguiente término NO está en el evento. Puedes utilizar la palabra
NOT o el carácter ! para realizar la misma operación
Ejemplo: java NOT elasticsearch o java !elasticsearch
Utiliza paréntesis para agrupar operadores. Por ejemplo, (NOT (elasticsearch OR kafka) java) OR python.
Filtros de etiquetas
También puedes filtrar los procesos mediante las etiquetas de Datadog, como host, pod, user y service. Ingresa filtros de etiquetas directamente en la barra de búsqueda o selecciónalos en el panel de facetas en la izquierda de la página.
Datadog genera de manera automática una etiqueta command, para que puedas filtrar por:
- Software de terceros, por ejemplo:
command:mongod, command:nginx - Software de gestión de contenedores, por ejemplo:
command:docker, command:kubelet) - Cargas de trabajo habituales, por ejemplo:
command:ssh, command:CRON)
Agregación de procesos
El etiquetado mejora la navegación. Además de todas las etiquetas existentes a nivel de host, los procesos se encuentran etiquetados por user.
Asimismo, los procesos en contenedores de ECS también se encuentran etiquetados por:
task_nametask_versionecs_cluster
Los procesos en los contenedores de Kubernetes se encuentran etiquetados por:
pod_namekube_pod_ipkube_servicekube_namespacekube_replica_setkube_daemon_setkube_jobkube_deploymentKube_cluster
Si se ha configurado el etiquetado de servicios unificado, env, service y version se seleccionan de manera automática.
Contar con estas etiquetas te permite vincular APM, logs, métricas y datos de proceso.
Nota: Esta configuración solo se aplica a entornos contenedorizados.
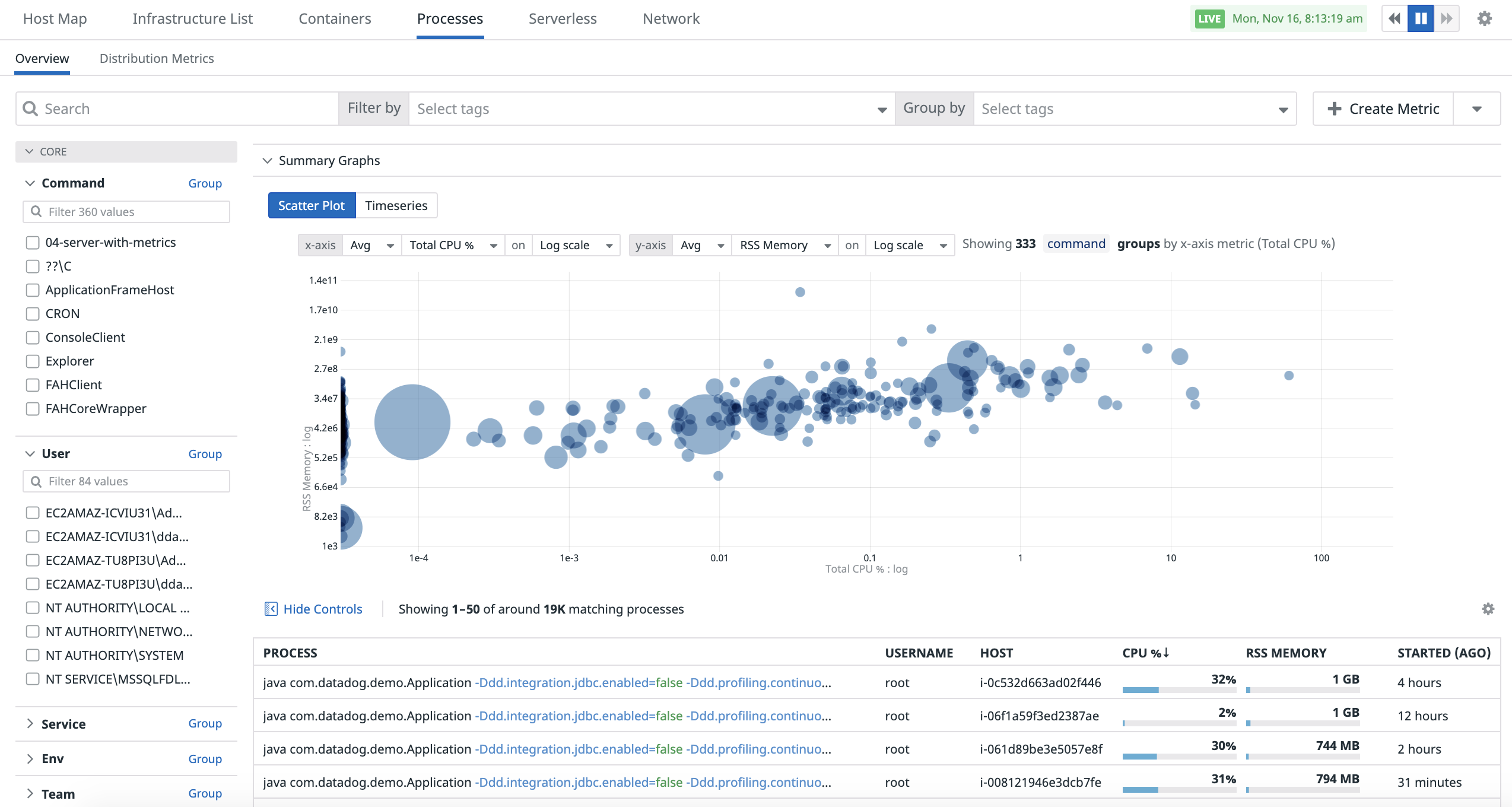
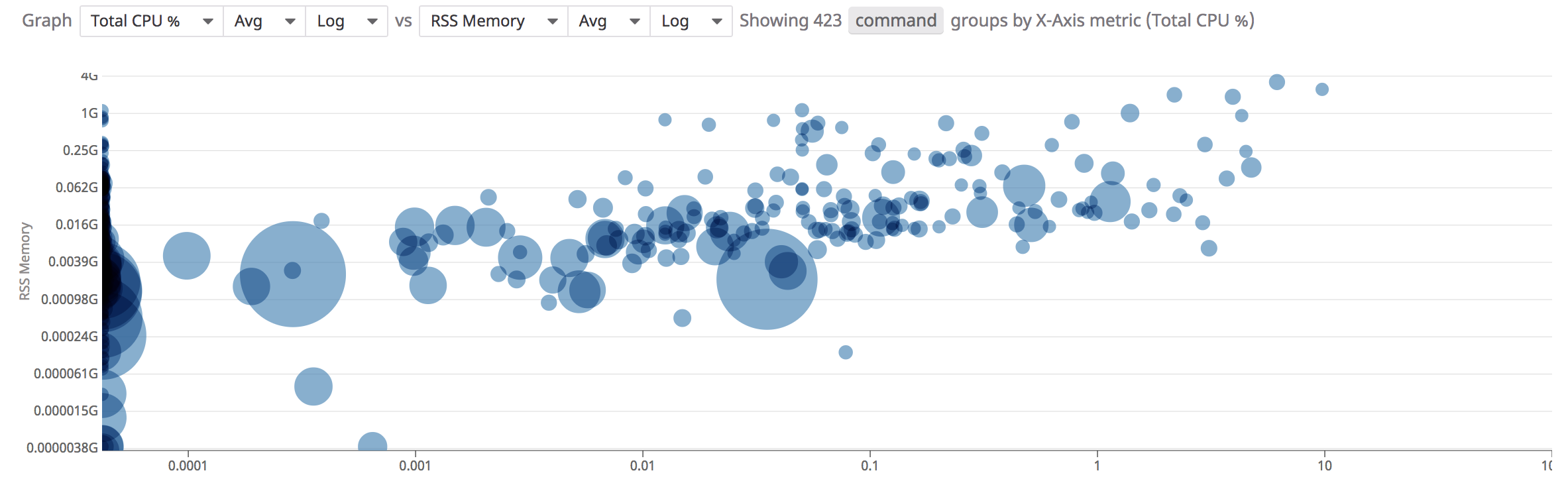
Diagrama de dispersión
Utiliza la analítica del diagrama de dispersión para comparar dos métricas entre sí a fin de comprender mejor el rendimiento de tus contenedores.
Para acceder a la analítica del diagrama de dispersión en la página de Procesos, haz clic en el botón Show Summary graph (Mostrar gráfica de resumen) y selecciona la pestaña «Scatter Plot» (Diagrama de dispersión):
De manera predeterminada, la gráfica se agrupa por la clave de etiqueta command. El tamaño de cada punto representa la cantidad de procesos en ese grupo y al hacer clic en un punto se muestran los pids y contenedores individuales que contribuyen al grupo.
La consulta en la parte superior de la analítica del diagrama de dispersión te permite controlar la analítica del diagrama de dispersión:
- Selección de métricas para mostrar.
- Selección del método de agregación para ambas métricas.
- Selección de la escala de los ejes X e Y (Lineal/Log).
Monitores de proceso
Utiliza el Monitor de Live Process para generar alertas basadas en el recuento de cualquier grupo de procesos en hosts o etiquetas. Puedes configurar alertas de proceso en la página de Monitores. Para obtener más información, consulta la documentación del Monitor de Live Process.
Procesos en dashboards y notebooks
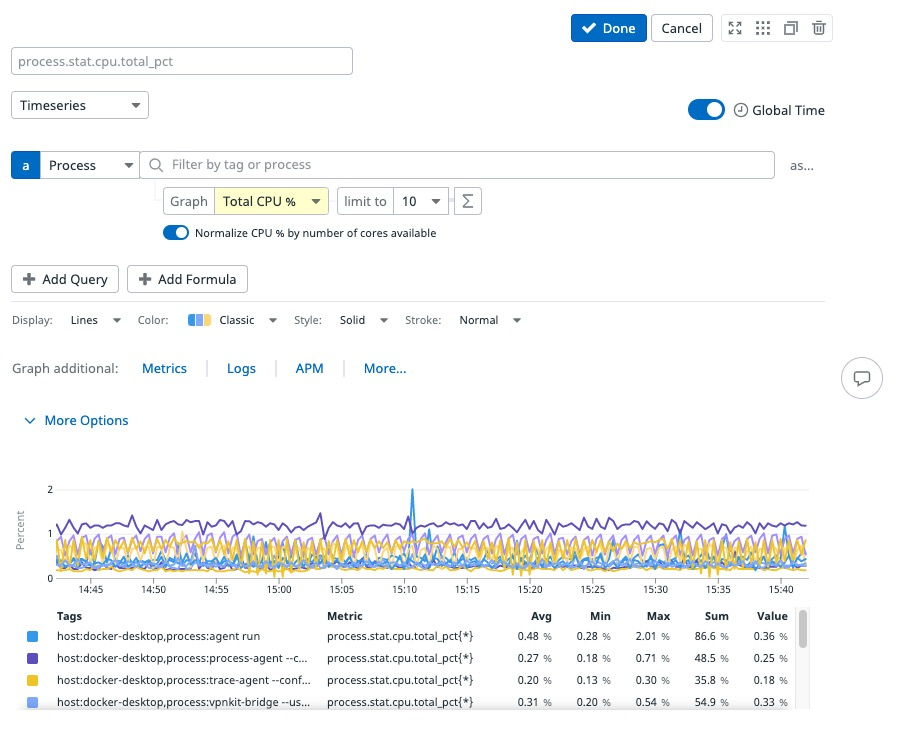
Puedes graficar las métricas de proceso en dashboards y notebooks mediante el widget de series temporales. Para configurar:
- Selecciona Processes (Procesos) como fuente de datos
- Filtra por cadenas de texto en la barra de búsqueda
- Selecciona una métrica de proceso para graficar
- Filtra usando etiquetas en el campo
From
Monitorización de software de terceros
Integraciones detectadas de manera automática
Datadog utiliza la recopilación de procesos para detectar de manera automática las tecnologías que se ejecutan en tus hosts. Esto identifica las integraciones de Datadog que pueden ayudarte a monitorizar dichas tecnologías. Estas integraciones detectadas de manera automática se muestran en la búsqueda de integraciones:
Cada integración puede adoptar uno de estos estados:
- + Detected (Detectada): esta integración no se ha habilitado en ninguno de los hosts que la ejecutan.
- ✓ Partial Visibility (Visibilidad parcial): esta integración se ha habilitado en algunos hosts, pero no todos la ejecutan.
Puedes encontrar los hosts que ejecutan la integración, pero en los que no se encuentra habilitada, en la pestaña Hosts del cuadro de integraciones.
Vistas de integración
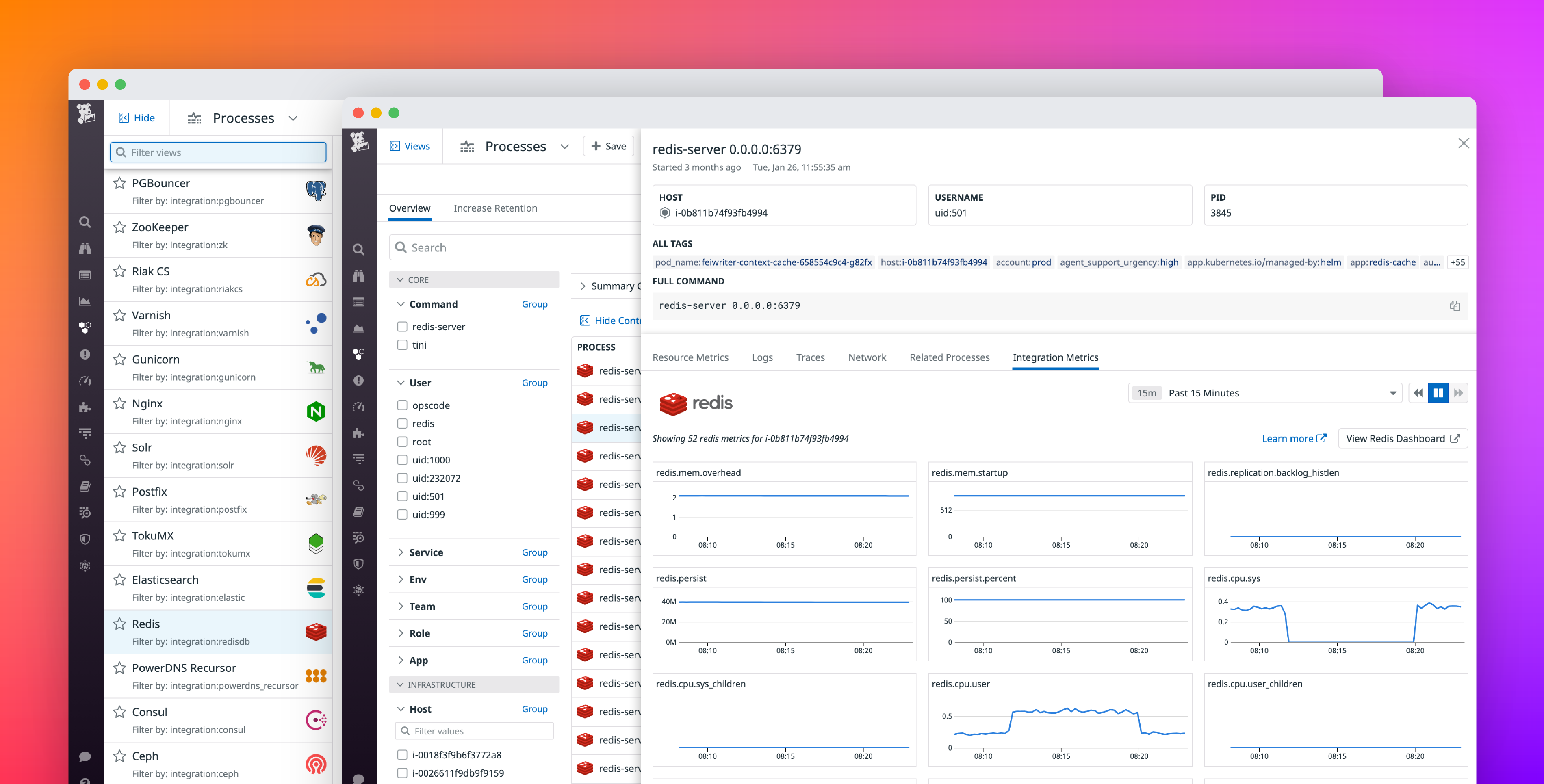
Una vez que se ha detectado un software de terceros, Live Processes ayuda a analizar el rendimiento de ese software.
- Para comenzar, haz clic en Views (Vistas) en la parte superior derecha de la página a fin de abrir una lista de opciones preestablecidas, incluidas Nginx, Redis y Kafka.
- Selecciona una vista para que la página solo abarque los procesos que ejecutan ese software.
- Al inspeccionar un proceso pesado, cambia a la pestaña Integration Metrics (Métricas de integración) para analizar el estado del software en el host subyacente. Si ya has habilitado la integración de Datadog relevante, puedes ver todas las métricas de rendimiento recopiladas de la integración para distinguir entre un problema a nivel de host y software. Por ejemplo, ver picos correlacionados en la CPU del proceso y la latencia de las consultas MySQL puede indicar que una operación intensiva, como un escaneo completo de la tabla, esté retrasando la ejecución de otras consultas MySQL que dependen de los mismos recursos subyacentes.
Puedes personalizar las vistas de integración (por ejemplo, al agregar una consulta para procesos de Nginx por host) y otras consultas personalizadas al hacer clic en el botón +Save (Guardar) en la parte superior de la página. Esto guarda tu consulta, selecciones de columnas de la tabla y configuraciones de visualización. Crea vistas guardadas para acceder con rapidez a los procesos que te interesen sin configuración adicional y compartir datos de procesos con tus compañeros de equipo.
Live Containers
Live Processes añade visibilidad adicional a los despliegues de tus contenedores al monitorizar los procesos que se ejecutan en cada uno de los contenedores. Haz clic en un contenedor en la página de Live Containers para ver su árbol de procesos, incluidos los comandos que está ejecutando y su consumo de recursos. Utiliza estos datos junto con otras métricas de contenedores para determinar la causa raíz de los contenedores o despliegues fallidos.
APM
En las trazas (traces) de APM, puedes hacer clic en el tramo (span) de un servicio para ver los procesos que se ejecutan en tu infraestructura subyacente. Los procesos de tramo de un servicio se correlacionan con los hosts o pods en los que se ejecuta el servicio en el momento de la solicitud. Analiza métricas de proceso como CPU y memoria RSS junto con errores a nivel de código para distinguir entre problemas de infraestructura específicos de la aplicación y más amplios. Al hacer clic en un proceso, accederás a la página de Live Processes. Los procesos relacionados no son compatibles con trazas de navegador y serverless.
Cuando inspeccionas una dependencia en la página de Network Analytics, puedes ver los procesos que se ejecutan en la infraestructura subyacente de los endpoints, como los servicios que se comunican entre sí. Utiliza los metadatos del proceso para determinar si una conectividad de red deficiente (indicada por una gran cantidad de retransmisiones de TCP) o una latencia de llamada de red alta (indicada por un tiempo de ida y vuelta de TCP alto) podría deberse a cargas de trabajo pesadas que consumen los recursos de esos endpoints y, por lo tanto, afectan al estado y eficiencia de su comunicación.
Monitorización en tiempo real
Mientras se trabaja de manera activa con Live Processes, las métricas se recopilan con una resolución de 2 segundos. Esto es importante para métricas volátiles como la CPU. En segundo plano, para el contexto histórico, las métricas se recopilan con una resolución de 10 segundos.
- La recopilación de datos en tiempo real (2 segundos) se desactiva después de 30 minutos. Para reanudar la recopilación en tiempo real, actualiza la página.
- En los despliegues de contenedores, el archivo
/etc/passwd montado en el docker-dd-agent es necesario a fin de recopilar nombres de usuario para cada proceso. Este es un archivo público y el Process Agent no utiliza ningún campo excepto el nombre de usuario. Todas las funciones, excepto el campo de metadatos user, funcionan sin acceso a este archivo. Nota: Live Processes solo utiliza el archivo passwd del host y no realiza la resolución de nombres de usuario para los usuarios creados dentro de contenedores.
Lectura adicional
Más enlaces, artículos y documentación útiles: