*Spring Boot v3.3.x y Spring Kafka v3.2.x utilizan Kafka Clients v3.7.x, que no admite la generación de retrasos. Para solucionarlo, actualiza la versión de Kafka Clients a v3.8.0 o posterior.
Kafka Streams es parcialmente compatible con Java y esto puede llevar a que se omitan mediciones de latencia.
Despliegues de Kafka compatibles
Instrumentar tus consumidores y productores con Data Streams Monitoring te permite ver tu topología y realizar un seguimiento de tus pipelines con métricas listas para usar, independientemente de cómo se despliega Kafka. Además, los siguientes despliegues de Kafka tienen más compatibilidad de integración, proporcionando más información sobre la salud de tu clúster de Kafka:
Data Streams Monitoring uses message headers to propagate context through Kafka streams. If log.message.format.version is set in the Kafka broker configuration, it must be set to 0.11.0.0 or higher. Data Streams Monitoring is not supported for versions lower than this.
Conectores de monitorización
Conectores de Confluent Cloud
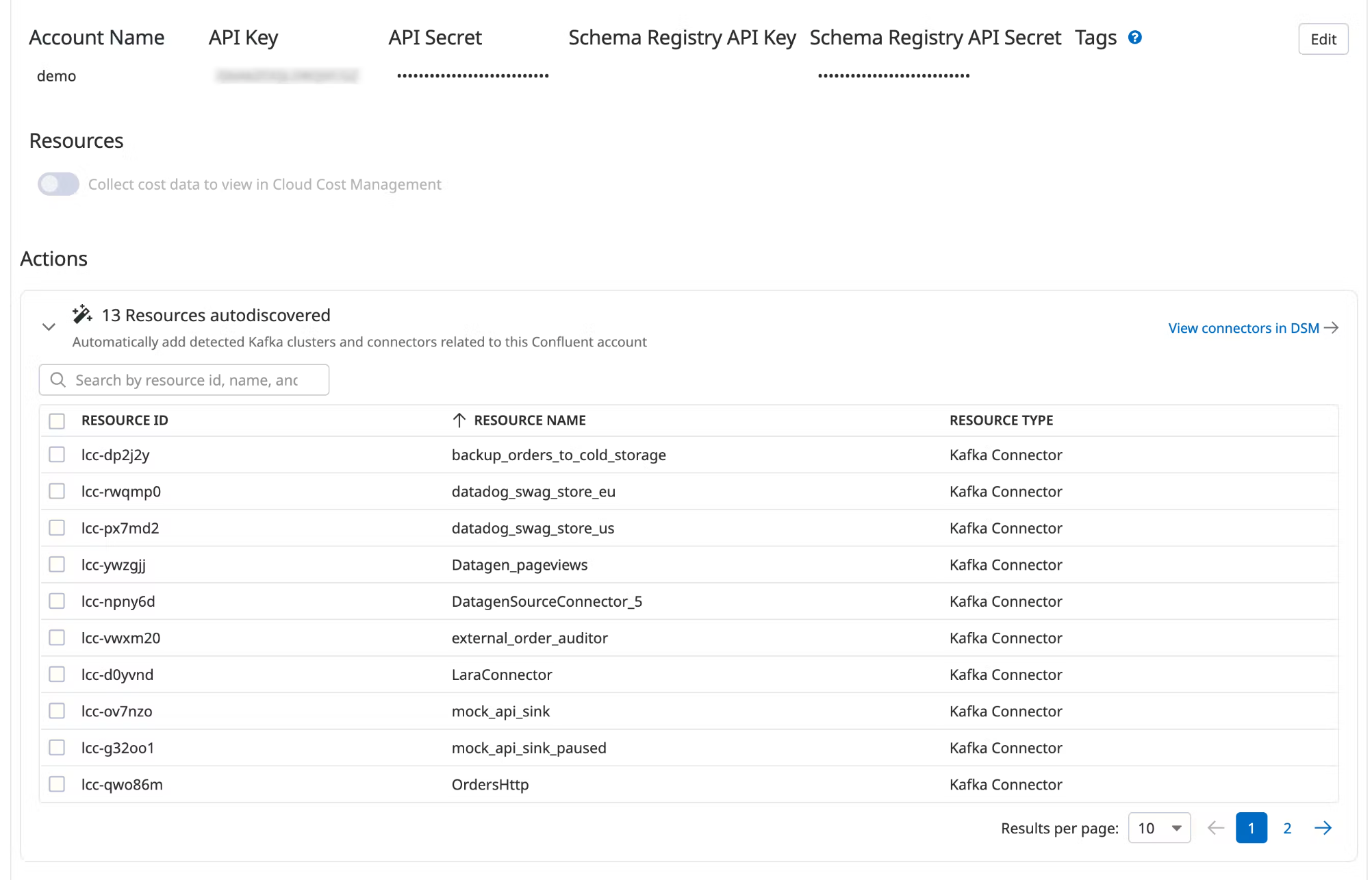
Data Streams Monitoring can automatically discover your Confluent Cloud connectors and visualize them within the context of your end-to-end streaming data pipeline.
Under Actions, a list of resources populates with detected clusters and connectors. Datadog attempts to discover new connectors every time you view this integration tile.
Select the resources you want to add.
Click Add Resources.
Navigate to Data Streams Monitoring to visualize the connectors and track connector status and throughput.
Data Streams Monitoring puede recopilar información de tus conectores de Kafka autoalojados. En Datadog, estos conectores se muestran como servicios conectados a temas de Kafka. Datadog recopila el rendimiento hacia y desde todos los temas de Kafka. Datadog no recopila estados de conectores o sumideros y fuentes de conectores de Kafka autoalojados.
Instalación
Asegúrate de que el Datadog Agent se está ejecutando en tus workers de Kafka Connect.
Asegúrate de que dd-trace (traza)-java está instalado en tus workers de Kafka Connect.
Modifica tus opciones de Java para incluir dd-trace-java en los nodos de tus workers de Kafka Connect. Por ejemplo, en Strimzi, modifica STRIMZI_JAVA_OPTS para añadir -javaagent:/path/to/dd-java-agent.jar.
1
2
rulesets:- %!s(<nil>) # Rules to enforce .
Solicitar una demostración personalizada
Empezando con Datadog
Ask AI
AI-generated responses may be inaccurate. Verify important info.